Агенты, кругом одни агенты…
Наши иконы самые красивые (с)
Предисловие: зачем вообще?
Как вы знаете - в ИТ нет понятия “ничего не делал”. У нас это называется - “ресерчил”. Это тот момент, когда, едва проснувшись перед дейли, вы конвульсивно пытаетесь придумать за несколько секунд, как обосновать вчерашнее безделие.
Но даже исследования ваши могут подразумевать наличие каких-то артефактов, которые возможно предъявить, уверяя, что вы работали над этим день и ночь. Не говоря уже о вполне прагматичных задачах - исследование каких-то новых тем, терминов, дабы произвести впечатление и поднять авторитет (и протянуть еще на контракте в наши скорбные времена).
Так вот как бы и тут лень должна помочь минимизировать затраты на подобные вещи - как раньше гуглить, забивать голову тоннами не самой релевантной информации, выписывать аккуратно в тетрадку самые важные тезисы и факты уже лениво - да в итоге вы неизбежно приходите к выводу, что большую часть времени потратили бесполезно, перерывая тонны лишней информации — ещё и не самой актуальной — так почему бы не позвать наших маленьких друзей агентов, которые всё это сделают за вас?
То есть цель какая -
- Качественный ресерч - самое свежее, самое актуальное, самое релевантное
- Ну теперь это нужно как обобщить и как можно более краткими и емкими тезисами резюмировать (у нас, кожаных, контекстное окно тоже как быстро перегружается)
- Еще если сопроводить красивыми иллюстрациями и диаграммами (визуально куда проще воспринять какие-то концепции)
Кстати - все нижеописанное подразумевает copilot agents и относится только к оным.
Не будем повторяться - в предыдущем посте основы работы с агентами описаны, мы помним проблемы - context rot (загнивание контекста), держим как можно меньше, агенты знают только то, что им нужно, и ещё как-то коммуницируют.
Собственно, задача стоит выжать максимум из такой схемы — да и проверим вообще, на что способна такая архитектура с доступными нам моделями. Может вообще весь замысел не стоит выделки. Хотя -
- Мы же решаем проблему поиска наиболее релевантной информации - понятно, модели и сами могут поискать своими инструментами web_fetch, но идея использовать Tavily (релевантнее и очищено), всякие MCP типа Git/Hugging Face/Context7 и прочее - особенно если нам нужны детали реализации чего-либо.
- Ну и попробуем с результатами что-то делать, как-то так обработать, чтобы извлечь самое полезное и отбросить всякую маркетинговую чушь и прочий мусор.
- Красиво бы обобщить в итоговом документе - максимально лаконичное изложение предмета исследований (желательно без галлюцинаций), да еще качественно иллюстрированное
Ну вот что-то такое:
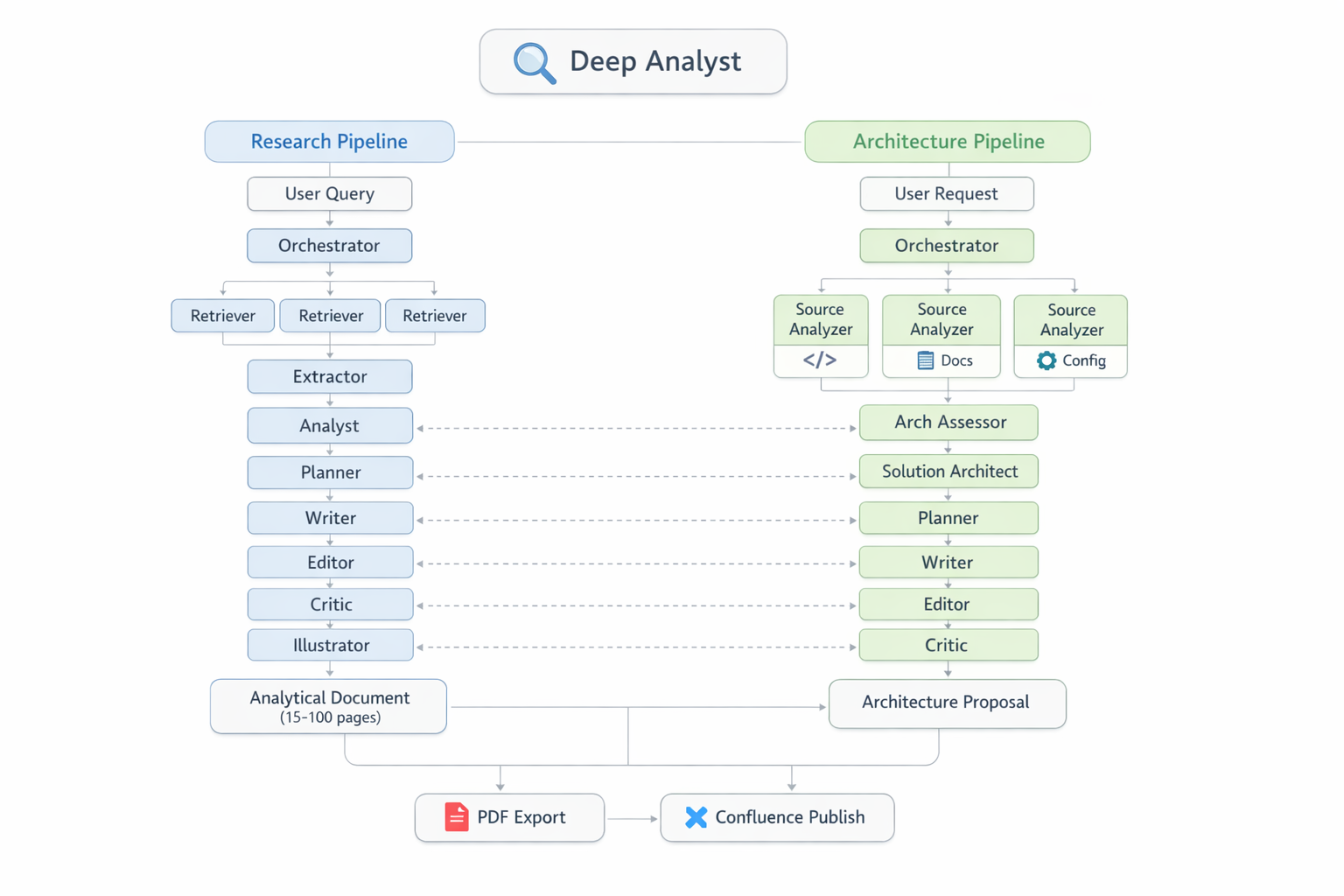 Общий вид платформы: два независимых пайплайна (Research и Architecture), 16 агентов, два Python state machine и система генерации иллюстраций PaperBanana
Общий вид платформы: два независимых пайплайна (Research и Architecture), 16 агентов, два Python state machine и система генерации иллюстраций PaperBanana
Это история про несколько версий архитектуры, набитые шишки и один символ двоеточия, который положил весь конвейер.
Эволюция:
Версия первая: «Ну ты же умный»
Это мы не рассматриваем даже — единственного агента. Потому что один агент, пытающийся одновременно искать, читать, анализировать и писать — это тот самый таджик, которого отправили и за шампанским, и на рынок, и к плите.
Версия вторая: «Пусть разговаривают»
Разделил на роли: Scout ищет, Extractor извлекает, Analyst анализирует. Каждый знает свою задачу. Проблема: как им общаться? Через return message sub-agent’а — текст для человека, не структурированные данные. Через файлы. Через промты. Через надежды и молитвы.
Версия третья: «Они сами справятся»
Спойлер: не справились. Каждый агент писал файлы в своём формате. Retriever записывал URL как - URL: https://..., а парсер ожидал 1. https://.... Один агент не мог прочитать то, что написал другой. Вавилонская башня, только вместо языков — форматы markdown.
Версия четвёртая: «Convention over Orchestration»
Файлы = протокол. Папки = маршрутизация. Каждый агент знает: читаю отсюда, пишу сюда. Стало лучше. Но агенты всё ещё отклонялись от инструкций, игнорировали логирование, придумывали свои форматы.
Версия 4.3: «Скрипт — мозг, агент — руки»
В итоге решил, что детерминизм пайплайна можно гарантированно обеспечить только кодом. Так появился Диспетчер — питон скрипт, единственный источник правды на всём комбинате. Stateless state machine. Диспетчер определяет порядок фаз, содержание промтов, правила валидации, логику повторов, логгирование. Его запускает агент-оркестратор — вызывает Диспетчер, получает инструкции и выполняет их.
А вот как выглядит итоговый конвейер — десять фаз, от декомпозиции темы до готового документа с иллюстрациями:
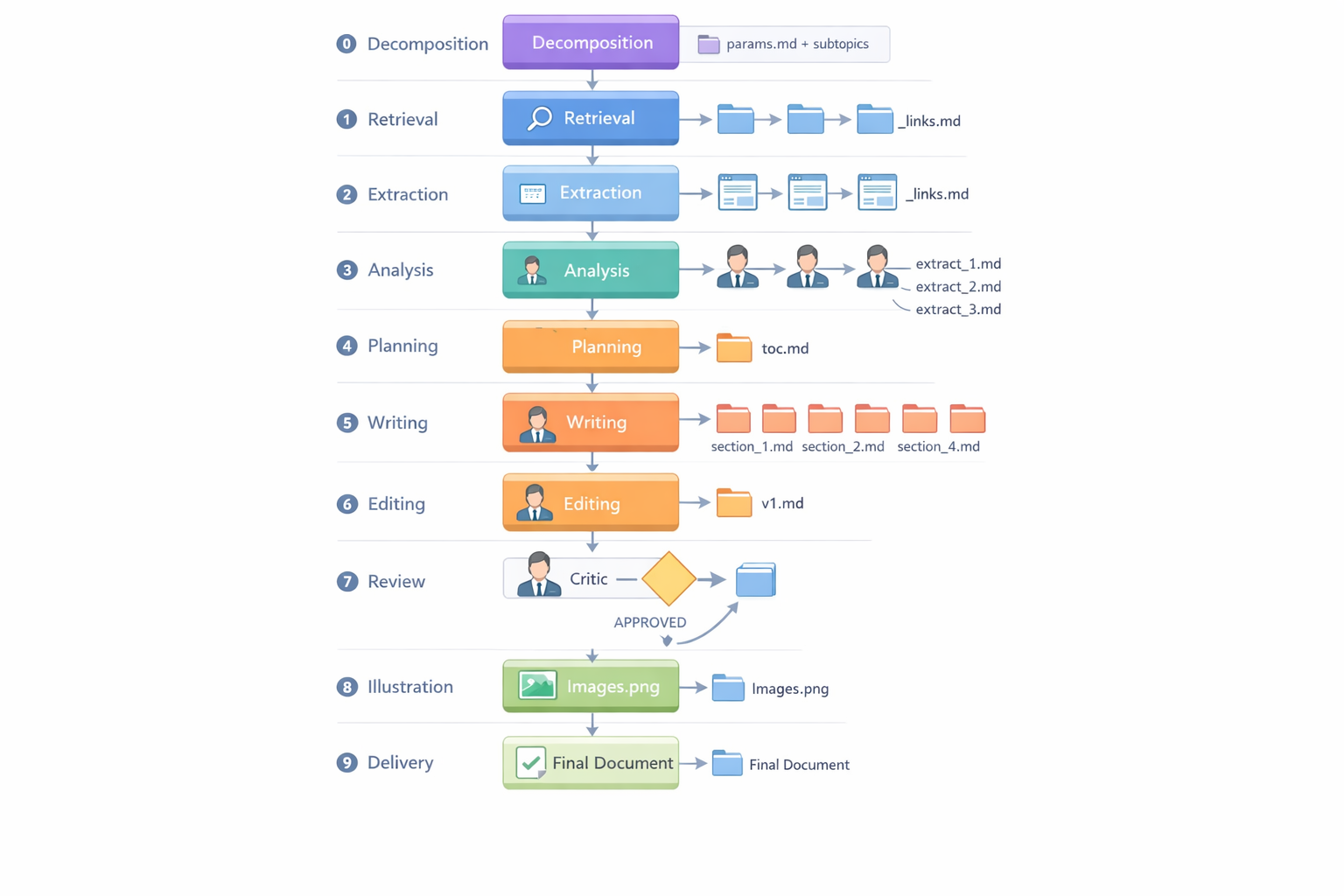 Исследовательский конвейер: 10 фаз от декомпозиции темы (Phase 0) до доставки готового документа с иллюстрациями (Phase 9). Ну и опционально всякая мелочь - конвертация в pdf, публикация на Confluence
Исследовательский конвейер: 10 фаз от декомпозиции темы (Phase 0) до доставки готового документа с иллюстрациями (Phase 9). Ну и опционально всякая мелочь - конвертация в pdf, публикация на Confluence
Кстати - про диаграммы и иллюстрации. Это была боль - самые крутые модели (я таковыми считаю Anthropic) более-менее справлялись с несложными mermaid и plantUML. draw.io уже совсем плохо — даже с примерами XML, иногда разве самые простые могли криво сгенерировать. В общем все плохо. Но тут вышел paperbanana https://github.com/llmsresearch/paperbanana — open-source фреймворк и всякие форки оного. Это не просто обёртка над image API. Это полноценный мультиагентный пайплайн из 6 агентов — пайплайн внутри пайплайна, если хотите:
- Retriever — выбирает релевантные примеры диаграмм из курируемой коллекции (13 эталонных стилей)
- Planner — по примерам генерирует детальное текстовое описание будущей диаграммы
- Stylist — правит описание под visual guidelines (палитра, layout, шрифты)
- Visualizer — рендерит описание в PNG через
gpt-image-1.5 - Critic — оценивает результат, даёт feedback
- Шаги 4–5 повторяются итеративно (по умолчанию 3 раунда)
Для тестирования пайплайна иллюстраций была выбрана тема «Жизнь белорусского бобра в пространстве и времени» — интереса ради. По-моему, вполне неплохо:
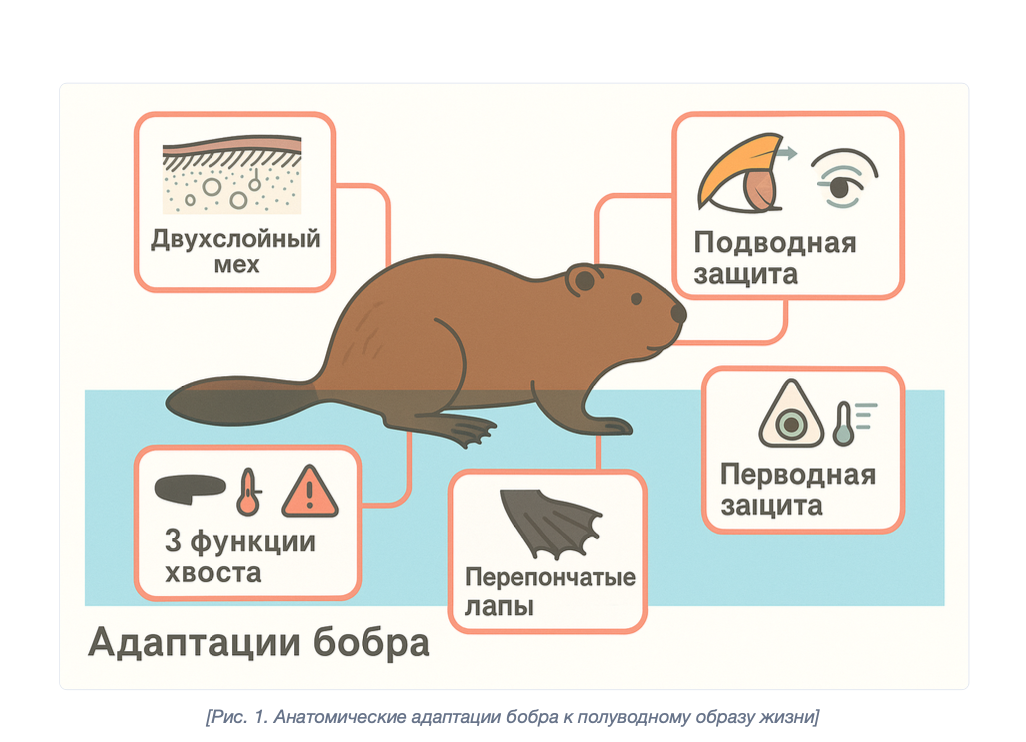 Анатомические адаптации бобра к полуводному образу жизни — сгенерировано PaperBanana
Анатомические адаптации бобра к полуводному образу жизни — сгенерировано PaperBanana
Набитые шишки
«Я записал!» — нет, не записал
Первое открытие, которое стоило мне двух дней: sub-agents, запущенные через runSubagent, ненадёжно работают с инструментами. На момент разработки (февраль 2026) они не могли писать файлы и вызывать MCP-инструменты — агент генерировал текст, выглядящий как вызов create_file или tavily_search, но это были галлюцинации: JSON-блоки, правильная структура, только ничего не выполнялось. Файлы на диске не появлялись, результаты поиска были выдуманы.
Важный нюанс: платформа быстро эволюционирует. В марте 2026 повторная проверка показала, что create_file и fetch_webpage у sub-agents уже работают. Но доверять этому безоговорочно я бы не стал — поведение может снова измениться с очередным обновлением VS Code или модели. Ну, или я ничего не понял.
Архитектурный вывод: Централизация I/O через orchestrator — не потому, что sub-agents «не могут», а потому, что так проще контролировать и валидировать. Orchestrator видит весь поток, может проверить output перед записью, залогировать, при необходимости — retry. Когда каждый sub-agent пишет файлы сам, вы теряете эту точку контроля. Но будем честны: это design choice, а не вынужденная мера.
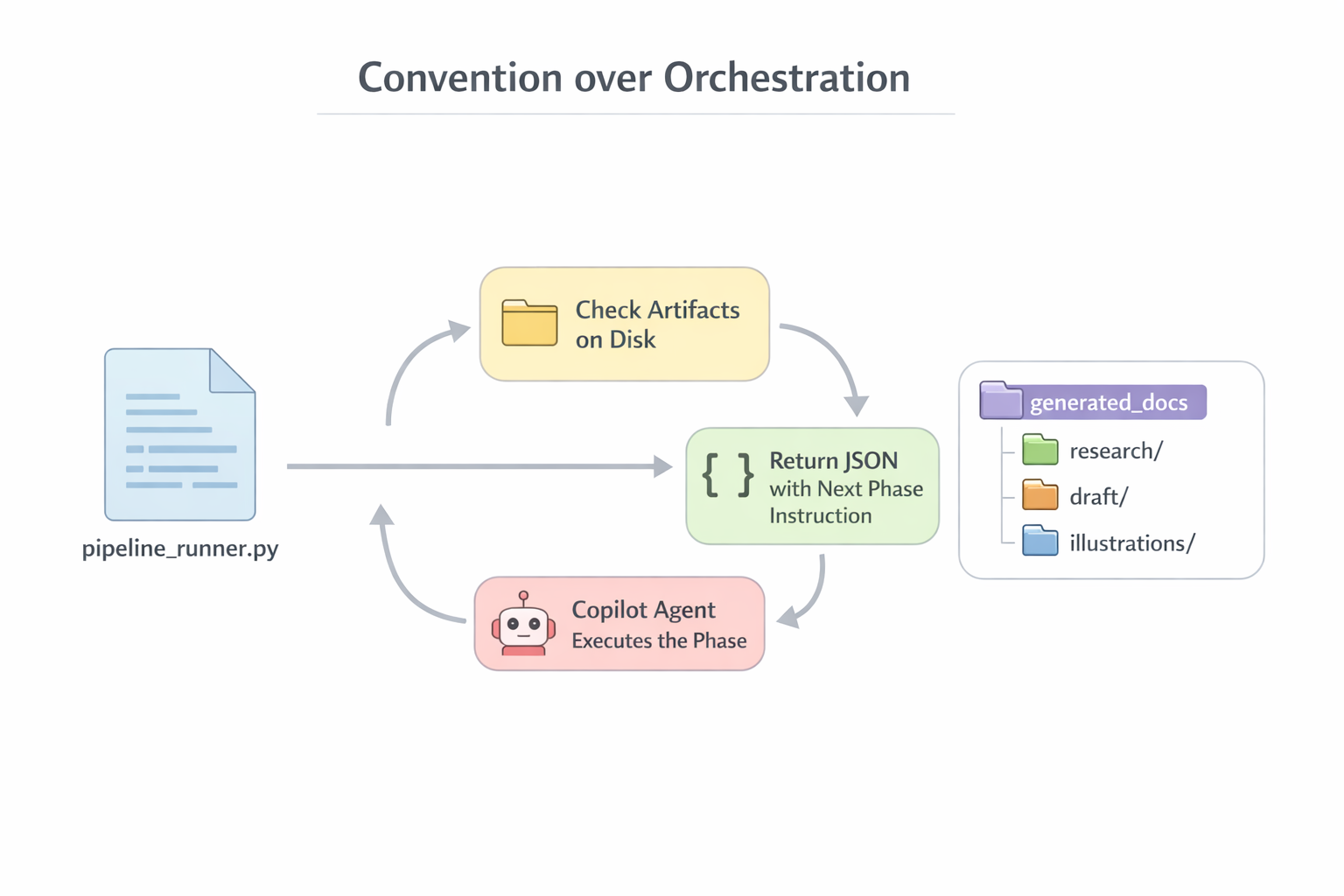 Детерминистическая оркестрация: Диспетчер решает «что делать», агент-исполнитель — «делает». Sub-agents только возвращают текст, всё I/O — через orchestrator
Детерминистическая оркестрация: Диспетчер решает «что делать», агент-исполнитель — «делает». Sub-agents только возвращают текст, всё I/O — через orchestrator
Склероз прогрессирующий
Контекстное окно — допустим 200K токенов. Звучит как много. На практике — представьте конвейерную ленту фиксированной длины. Каждый tool call — и запрос, и ответ — ложится на ленту и остаётся навсегда. Удалить нельзя. Сжать нельзя. К седьмой фазе из десяти лента забита под завязку, и ваш блестящий инженер начинает забывать, зачем он здесь.
Причём деградация не внезапная. Сначала агент перестаёт логировать (инструкции по логированию — в конце промта, а конец он уже «не видит»). Потом начинает путать форматы файлов. Потом забывает ограничения по стилю. А в конце просто обрывается на полуслове и просто умирает, не информируя вас ни о чём.
Каталог аварий: лучшее из худшего
Галлюцинация: «FDA вместо Copilot»
Фаза 5, написание секций. Writer sub-agent получает промт: «напиши раздел про архитектуру агентного цикла GitHub Copilot». В промте указаны пути к extract-файлам — тем самым, где лежит собранный ресерч. Но пути — это не контент. Чтобы их прочитать, sub-agent должен сам вызвать read_file. А мы помним из раздела выше: sub-agents ненадёжно работают с инструментами.
Что происходит, когда модель не получает grounding-данных и не читает источники? Она откатывается на training data и уверенно генерирует текст на произвольную тему. В нашем случае — 1070 строк про «Tamper-Proof Clinical-Trial Document Integrity System» с FDA (американский регулятор медицины!), W3C, Apache Tika и SHA-3-256. Уверенным академическим тоном. С таблицами. С псевдокодом. Ни единого слова про GitHub Copilot.
Это как если бы вы попросили повара приготовить борщ, а он выдал вам диссертацию по квантовой физике. С рецензией. Во французском оформлении.
Решение: check_relevance() — проверка, что хотя бы 30% ключевых слов темы встречаются в output’е. Если нет — retry с warning «CRITICAL: Stay on topic». Детский сад? Именно. Но работает. А в последующих версиях контент extract’ов стали вставлять прямо в промт — не рассчитывая на то, что sub-agent сам сходит и прочитает.
Двоеточие Судного Дня
Как конвейер узнаёт, что именно исследовать? Через params.md — markdown-файл, который Оркестратор генерирует на основе запроса пользователя. Это входная точка всего пайплайна: тема исследования, язык, целевая аудитория, бюджет страниц, стиль изложения. Диспетчер парсит этот файл и раздаёт параметры каждой фазе. Формат простой: - **Key:** value.
Так вот. Regex для парсинга ожидал двоеточие СНАРУЖИ звёздочек: **Key**: value. А агент, заполнявший шаблон, поставил двоеточие ВНУТРИ: **Key:** value. Один символ — и все параметры возвращали defaults. Тема «Research» вместо реальной. Бюджет «25 страниц» вместо заданных 15. Пайплайн честно генерировал 25 страниц про «Research» — и вы даже не сразу понимали, что что-то пошло не так.
Урок: Один символ может сломать весь конвейер. Regex-парсеры — это критическая инфраструктура, и она нуждается в тестах.
Бесконечный цикл URL-валидации
count_urls() считал ссылки через re.findall(r'https?://', text). Но fetch_webpage иногда возвращал file:// URI. Парсер их не видел → считал файл пустым → отправлял на retry → retry находил те же URL → парсер снова не видел → и так по кругу. 15 минут, 4+ ручных вмешательства. Изящный regex для распознавания URL — и вот ваш конвейер крутит шестерёнки вхолостую.
Двойная запись: как конвейер пожирал свою память
Это главный архитектурный баг, обнаруженный после трёх запусков.
Смотрите: orchestrator вызывает fetch_webpage("https://docs.github.com/...") и получает 5K символов контента. Контент ложится в history. Затем orchestrator вызывает create_file("extract_1.md", тот_же_контент). Тот же контент ложится в history второй раз. Не ссылка на файл, не хеш — полная копия.
Масштаб бедствия:
- Фаза 2 (извлечение): 30 URL × 5.7K средний × 2 = ~340K символов дубликатов
- Фаза 5 (написание): 8 секций × 9K средний × 2 = ~144K
- Фаза 6 (merge): 71K × 2 = ~142K
- Итого: ~411K символов — половина контекста — чистые дубликаты
Это как если бы на вашем конвейере каждая деталь проходила через станок дважды: один раз реально, второй раз — призрак детали, который всё равно занимает место на ленте.
Решение очевидное, но требующее изменений: вынести тяжёлые операции в отдельные Python-скрипты, которые делают I/O самостоятельно и возвращают orchestrator’у одну строку: «✓ готово, 4200 слов». Вместо 5K символов в контексте — 30 символов.
Уверенная неточность: галлюцинации на службе
LLM не говорит «не знаю». Никогда. Вместо этого он:
-
Изобретает правдоподобные CLI-флаги.
claude --headless --prompt— звучит разумно, выглядит правильно. Только правильный флаг —claude -p. А--headlessне существует. -
Путает похожие, но разные вещи. Subagents (Agent tool, hub-and-spoke) и Agent Teams (TeammateTool, mesh) — два совершенно разных механизма. Агент уверенно описывал один, называя другим. С таблицей сравнения. С примерами кода. Всё ложь.
-
Генерирует таблицы с уверенным тоном и ложными данными. «web_search», «notebook_edit» — таких инструментов нет ни в одном из исследуемых фреймворков. Но таблица выглядела убедительно. Я бы и сам поверил, если бы не полез проверять в исходники.
Единственная защита — сверка с primary sources. Исходный код. CLI --help. Официальная документация. Всё остальное — потенциальная галлюцинация, даже если написано уверенно, структурированно и с кодовыми блоками.
Потеря процедурных знаний, или Амнезия агента
Вот вам драма в трёх актах.
Акт 1: Фазы 1–7 выполнены. Пять из шести иллюстраций сгенерированы правильной командой: paperbanana_generate.py --direct "описание" "output.png". Агент знает wrapper-скрипт, имя провайдера, формат вызова. Всё работает.
Акт 2: Контекст переполнен. Разговор обрывается. Начинаю новую сессию.
Акт 3: Новый агент — это буквально тот же блестящий инженер, но с полной амнезией. Он не помнит wrapper. Он пытается вызвать paperbanana.cli --direct — флаг --direct не существует в raw CLI. Ошибка. Пробует --provider openai — нужен openai_imagen. Ошибка. --vlm-provider google — нужен API-ключ Google, которого нет. Ошибка. Пять попыток, прежде чем случайным перебором нашёлся рабочий вариант.
Одна иллюстрация. Пять попыток. Потому что контекстное окно — это не просто лимит на текст. Это вся оперативная память вашего работника. Перезапустили разговор — стёрли всё.
Девять принципов, нажитых кровью
За пять версий и пару десятков запусков выкристаллизовались принципы, которые актуальны на сегодняшний день.
1. Код — не «инструкции»
Если что-то должно выполниться гарантированно — оно должно быть в коде, а не в промте. Агент будет игнорировать инструкции — вопрос когда, не если. Логирование? Python logging. Порядок фаз? Диспетчер. Форматы файлов? Regex-парсеры. Retry-логика? can_retry() с persistence. Слово «должен» для агента — вежливая рекомендация.
2. Sub-agent = генератор текста (by design)
Sub-agents могут вызывать инструменты — create_file, fetch_webpage уже работают. Но мы осознанно ограничиваем их до генерации текста. Промт говорит «RETURN as markdown», не «write to file». Почему? Orchestrator видит весь поток, валидирует output перед записью, логирует, делает retry. Когда каждый sub-agent пишет файлы сам — вы теряете эту точку контроля. А ещё: каждый tool call sub-agent’а — это токены в контексте orchestrator’а. Чем меньше tool calls внутри sub-agent’а, тем больше контекста останется на полезную работу.
3. Файлы = протокол
Единственный надёжный канал между агентами — файлы на диске с фиксированным форматом. _links.md — пронумерованный список URL. extract_*.md — заголовок + тело. toc.md — ## NN. Title — Pages: N — Sources: path. Всё парсится одним regex’ом. Всё предсказуемо.
4. Валидация после каждой фазы
Пустой output одной фазы = мусор на всех следующих. Скрипт проверяет: файлы есть, word count в норме, URL хватает, контент релевантен. Без этого ваш конвейер гонит брак, а вы узнаёте об этом только на финальной приёмке.
5. Параллелизм через изоляцию
Одна подтема = одна папка = один агент. Race conditions невозможны, если каждый пишет в своё. Retry одной фазы не запускает следующую параллельно. Просто, скучно, работает.
6. Не crash, а graceful degradation
Подтема без extract’ов — пропускается. Writer написал мусор — retry. ToC не парсится — retry с форматом. Две ревизии не помогли — принимаем как есть. Иллюстрация не сгенерировалась — документ без неё. Управляющий комбинатом не паникует при аварии станка. Он перенаправляет поток и продолжает.
7. Один regex может сломать всё
Парсеры — критическая инфраструктура. Двоеточие внутри bold’а, file:// вместо https://, пробел перед маркером — каждый из этих случаев блокировал пайплайн. Тесты для парсеров — не роскошь.
8. Контекстное окно — физическое ограничение
Это не баг. Не workaround. Это фундаментальное физическое ограничение, как размер цеха на вашем комбинате. В цех влезает определённое количество станков — и всё, стены не раздвинешь.
VS Code Copilot Chat работает по модели «append-only history». Каждый вызов инструмента — запрос и ответ — ложится в историю и остаётся навсегда. Удалить нельзя. Сжать нельзя. Контекстное окно Claude Sonnet — ~200K токенов. Звучит огромно. Вот как оно заполняется на реальном запуске 15-страничного документа:
- Baseline (system prompt, agent config, memory): ~8K — ещё не начали работать, а 4% уже занято.
- Фаза 1 (поиск URL): +7K — терпимо.
- Фаза 2 (извлечение контента): +70K — и вот тут начинается веселье. 30 URL, каждый скачан через
fetch_webpage, каждый записан черезcreate_file. Одни и те же данные — дважды в контексте. - Фазы 3–5 (анализ, планирование, написание): +60K — sub-agents возвращают текст, orchestrator записывает файлы. Опять двойная порция.
- Фаза 6 (merge): +38K — Editor собирает документ из секций. 71K символов контента + 71K в create_file = дубль.
- Фазы 7–9 (рецензия, иллюстрации): +11K — мелочь, но мы уже на пределе.
Итого: ~197K из 200K. Конвейер дотягивает до финиша на последних каплях контекста, как машина, въезжающая на заправку с горящей лампочкой.
А теперь главное. Деградация начинается задолго до лимита. При 50K+ агент хуже рассуждает. При 100K+ — начинает «забывать» инструкции из начала промта. При 150K+ — пропускает обязательные шаги и путает файлы. Это не обрыв — это плавное угасание, как у лампочки на диммере. И вы не сразу замечаете, что свет стал тусклее.
Пайплайн из 10 фаз не помещается в одну сессию — это физика. Session boundaries — такой же обязательный элемент дизайна, как стены между цехами на заводе. К счастью, Диспетчер — stateless state machine: он определяет текущую фазу по файлам на диске, не по памяти. Перезапустили разговор, вызвали next — Диспетчер смотрит на ленту и сразу понимает, что делать дальше.
Но одного разбиения мало. Нужно ещё уменьшать расход контекста внутри каждой сессии. Главный виновник — double write: orchestrator получает данные (fetch_webpage / runSubagent return) и тут же передаёт те же данные в create_file. Одинаковый контент — дважды в history. На это уходит ~110K токенов — больше половины бюджета. Решение: вынести тяжёлые операции в Python-скрипты, которые сами делают I/O и возвращают orchestrator’у одну строку: «✓ extract_1.md — 4200 words». Вместо 5K символов в контексте — 30.
9. Процедурные знания летучи
Всё, что агент «узнал» в ходе работы — точные CLI-команды, workaround’ы, имена провайдеров — испаряется при перезапуске сессии. Критические рецепты должны быть зафиксированы в файлах, но это и так очевидно.
Вместо заключения
Работает ли это? Более-менее. Последний запуск — 15-страничный документ с шестью иллюстрациями, отрецензированный и одобренный. Без ручного написания ни единого абзаца.
Но — контекст всё ещё порой переполняется. Агенты всё ещё галлюцинируют. Regex всё ещё ломается на неожиданных форматах. Но каждый запуск — это данные. Каждая авария — принцип. Каждый принцип — строчка в Диспетчере.
И в этом, пожалуй, главный урок: управлять комбинатом из Железных Болванов — это не про «попросил и получил». Это инженерная дисциплина. С тестами, валидацией, retry-логикой, session boundaries и параноидальными инструкциями.
А кому интересно покопаться — репозиторий открыт.