Как работают трансформеры: понятное объяснение
Так, вернёмся же опять к трансформерам и попробуем как-то разобраться как они работают - как обычно, минимум заумных формул и сгенерированного ИИ текста. Автор не претендует на статус истины в последней инстанции и вполне может где-то и приврать
1. Зайдем с чего то попроще
А давайте освежим в памяти как работали рекуррентные сети - то есть «возвращающиеся к себе», как тут не вспомнить Гегеля и его Абсолютный Дух что проходит путь отчуждения от себя и возвращения к себе же — таки гегелевская рекуррентность в чистом виде.
Как работала RNN: передача записки по цепочке
Представьте четырёх ваших коллег, сидящих в ряд. Каждый видит только одно слово и получает записку от соседа слева — краткий пересказ того, что было до него. Его задача: прочитать своё слово, дополнить записку и передать дальше.
Вот фраза - «кошка сидела на крыше»:
Первый 🧑 видит слово «кошка». Записки от соседа нет (он первый). Пишет на стикере: «речь о кошке» → передаёт вправо.
Второй 🧑 видит слово «сидела», получает стикер «речь о кошке». Стирает, дописывает, передаёт: «кошка сидела» → вправо.
Третий 🧑 видит «на», получает стикер, обновляет: «кошка сидела на…» → вправо.
Четвёртый 🧑 видит «крыше», обновляет: «кошка сидела на крыше».
Таким образом каждый шаг зависит от предыдущего, информация передаётся строго последовательно через единственный стикер (вектор скрытого состояния).
Дальше что?
Конечно, на настоящем стикере внутри нейросети никаких слов нет — только числа: фиксированный вектор из, скажем, 512 значений. Вспоминаем про эмбеддинги — то есть многомерное смысловое пространство (подробнее здесь). Каждый человек в цепочке получает эти 512 чисел, видит своё слово — и записывает на стикер новые 512 чисел, в которых теперь закодирован смысл всего, что было до него. Не «кошка сидела», а одно числовое представление — некие координаты в смысловом пространстве, где закодировано и то, что речь о кошке, и то, что она что-то делает, и что это происходит где-то наверху.
Но стикер имеет фиксированный размер. Пока фраза короткая, всё умещается. Но представьте предложение из 50 слов: к 40-му слову человек в цепочке получает стикер, на котором уже 39 раз что-то стирали и дописывали поверх. Информация о первых словах размылась. Сеть буквально забывает начало предложения.
И кроме того скорость. Человек 2 не может начать работу, пока Человек 1 не передаст стикер. Человек 3 ждёт Человека 2. Все стоят в очереди. А у нас еще и GPU, которые рассчитаны на тысячи параллельных операций, такая последовательная работа — как-то не очень.
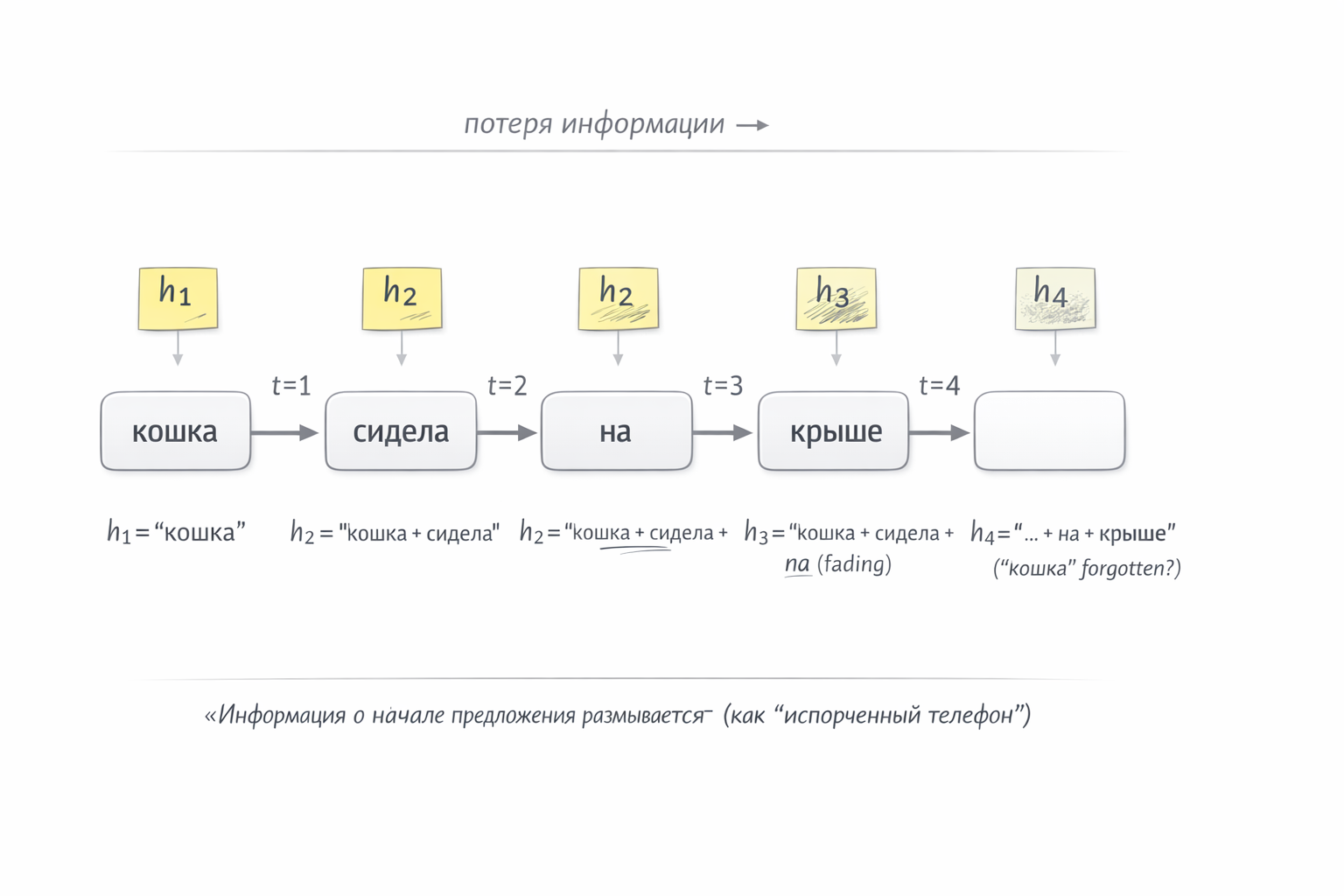
Рис. 1. Как RNN обрабатывает фразу «кошка сидела на крыше» — передача стикера по цепочке
Трансформер: все видят всё
А вот теперь появляется трансформер, который убирает вышеописанную схему полностью — вместо четырёх человек, передающих записку, представьте круглый стол: все четыре слова лежат перед моделью одновременно, и каждое может напрямую посмотреть на любое другое. Слову «крыше» не нужно ждать, пока информация о «кошке» доползёт через промежуточные шаги — оно видит «кошку» напрямую.
Соответственно:
- Мы не теряем информацию — каждое слово имеет прямой доступ к каждому другому, без посредников.
- Полная параллельность — все слова обрабатываются одновременно, загружая GPU на полную.
И ещё раз проиллюстрируем с помощью моего агента на базе PaperBanana
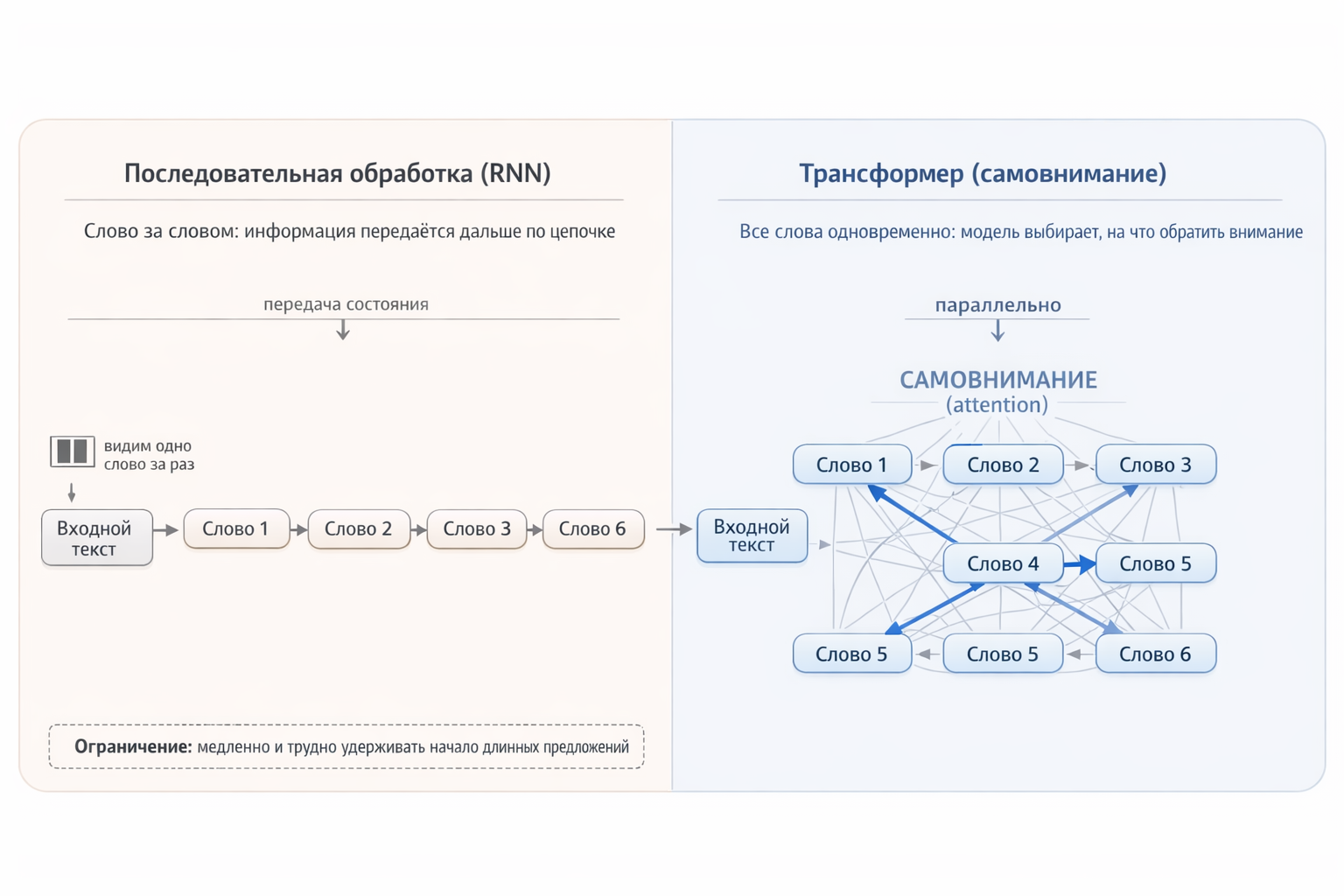
Рис. 2. Последовательная обработка vs. параллельный «взгляд» трансформера
2. Общая архитектура: слой за слоем
Трансформер — это стопка одинаковых слоёв (обычно от 12 до 96+). Каждый слой содержит два блока:
- Механизм внимания (Self-Attention) — мы уже в нем разбирались в статье по ссылке выше, тут не будем углубляться. То есть определяем какие слова в предложении связаны между собой и как.
- Полносвязная сеть (FFN — Feed-Forward Network) — а вот тут интересно. Оная обрабатывает каждое слово по отдельности, «обогащая его» какими-то знаниями. Вот с этим бы разобраться.
В теории мы знаем что слова промпта проходят через все слои снизу вверх — и что на каждом уровне модель строит всё более глубокое понимание текста. Вот только что значит «глубокое понимание»? Что модель вообще может «понимать»? Мы не можем понять, как мы что-то «понимаем» — ещё Гинзбург (лауреат Нобелевской премии по физике) считал феномен сознания одной из ключевых загадок физики. Бехтерева Наталья — директор Института мозга человека РАН, полвека изучавшая мозг, писала: «Я часто думаю о мозге так, будто он — отдельный организм, как бы „существо в существе"» — и при этом честно признавалась, что природа сознания так и осталась для неё загадкой. А Татьяна Черниговская — нейролингвист, профессор СПбГУ, член РАН — и вовсе считает сознание главной проблемой Вселенной: никакая нейронаука пока не объяснила, откуда берётся субъективный опыт. На сим минутка нарциссизма от авторской эрудиции закончена.
Что входит и что выходит
На вход трансформер получает текст, разбитый на токены (слова или части слов). Каждый токен превращается в числовой вектор — эмбеддинг — размером, например, 4096 чисел. Это стартовое числовое представление слова.
На выходе — обновлённый вектор для каждого входного токена. Для предсказания следующего слова берётся вектор последнего токена (а он содержит как бы смысл всего текста) — он проходит через финальный линейный слой и дальше фаза decode. То есть представьте себе таблицу размера вокабуляра модели — пусть будет 100 000 токенов. В таблице 4096 колонок — в каждом поле число, определяющее координату данного токена согласно одному из 4096 смысловых измерений. Дальше этот самый вектор (он же вектор скрытого состояния) мы умножаем на таблицу, то есть вектор × матрица, и получаем на выходе 100 000 чисел (логитов, опустим всякие нормализации softmax, нас интересует концептуальное понимание) — по одному на каждый токен вокабуляра. Чем выше число — тем выше, по мнению модели, вероятность того, что именно этот токен будет следующим. К сожалению paperbanana генерирует много ошибок в надписях на русском, но вы поймёте:
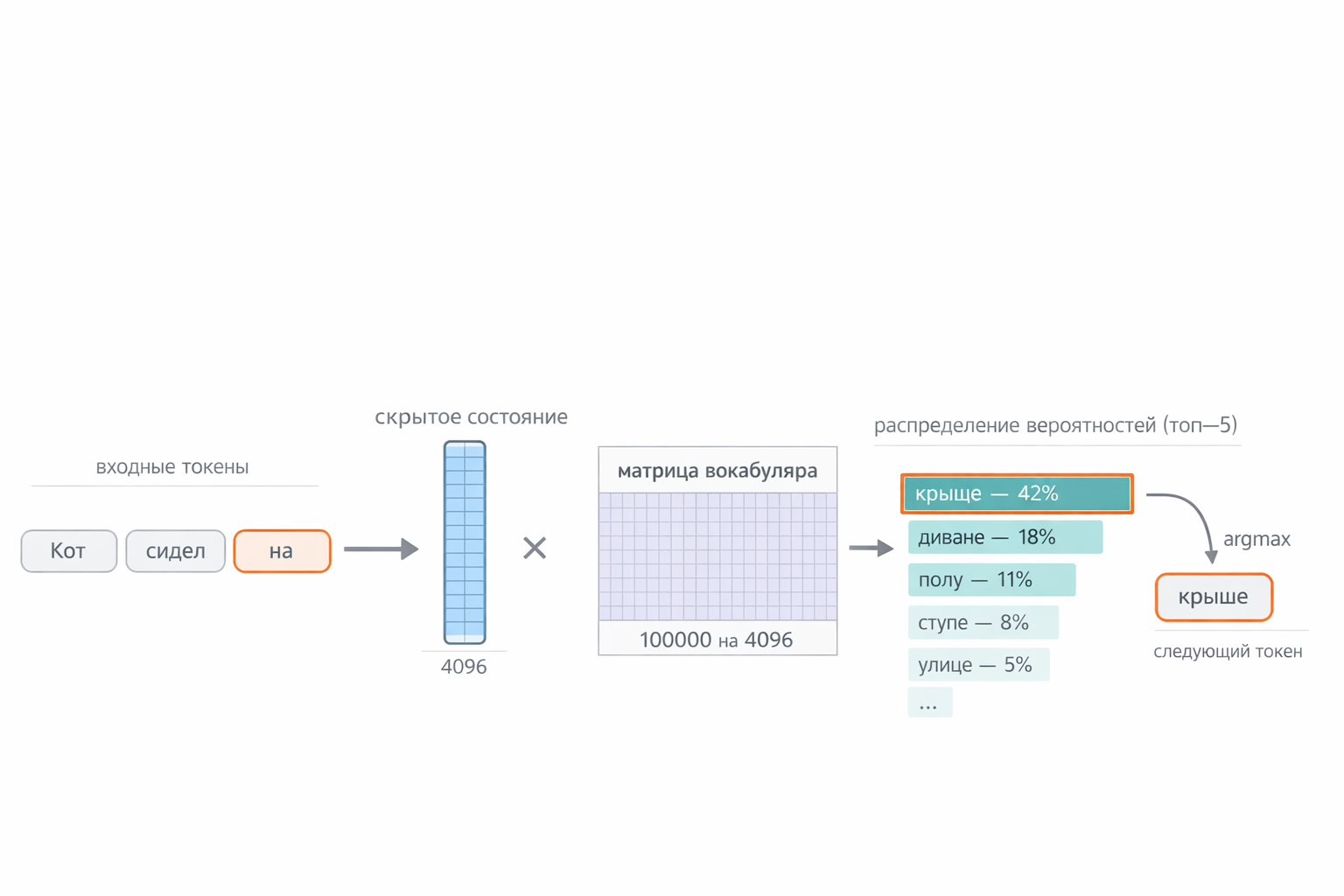
Рис. 3. Входной текст «Кот сидел на» разбивается на 3 токена, последний («на») выделен. Его вектор скрытого состояния (4096 чисел) умножается на матрицу вокабуляра (100 000 × 4096) → 100 000 логитов → топ-5 кандидатов: крыше 42%, диване 18%, полу 11%, стуле 8%, улице 5% → следующий токен «крыше».
3. FFN: «память знаний» трансформера
Где находится FFN в трансформере
FFN (Feed-Forward Network) — это часть каждого слоя трансформера. Каждый слой трансформера выполняет два действия подряд:
- Внимание (слова общаются друг с другом)
- FFN (каждое слово обрабатывается индивидуально). Эти два блока всегда идут парой и связаны остаточными связями (результат прибавляется к входу, а не заменяет его).
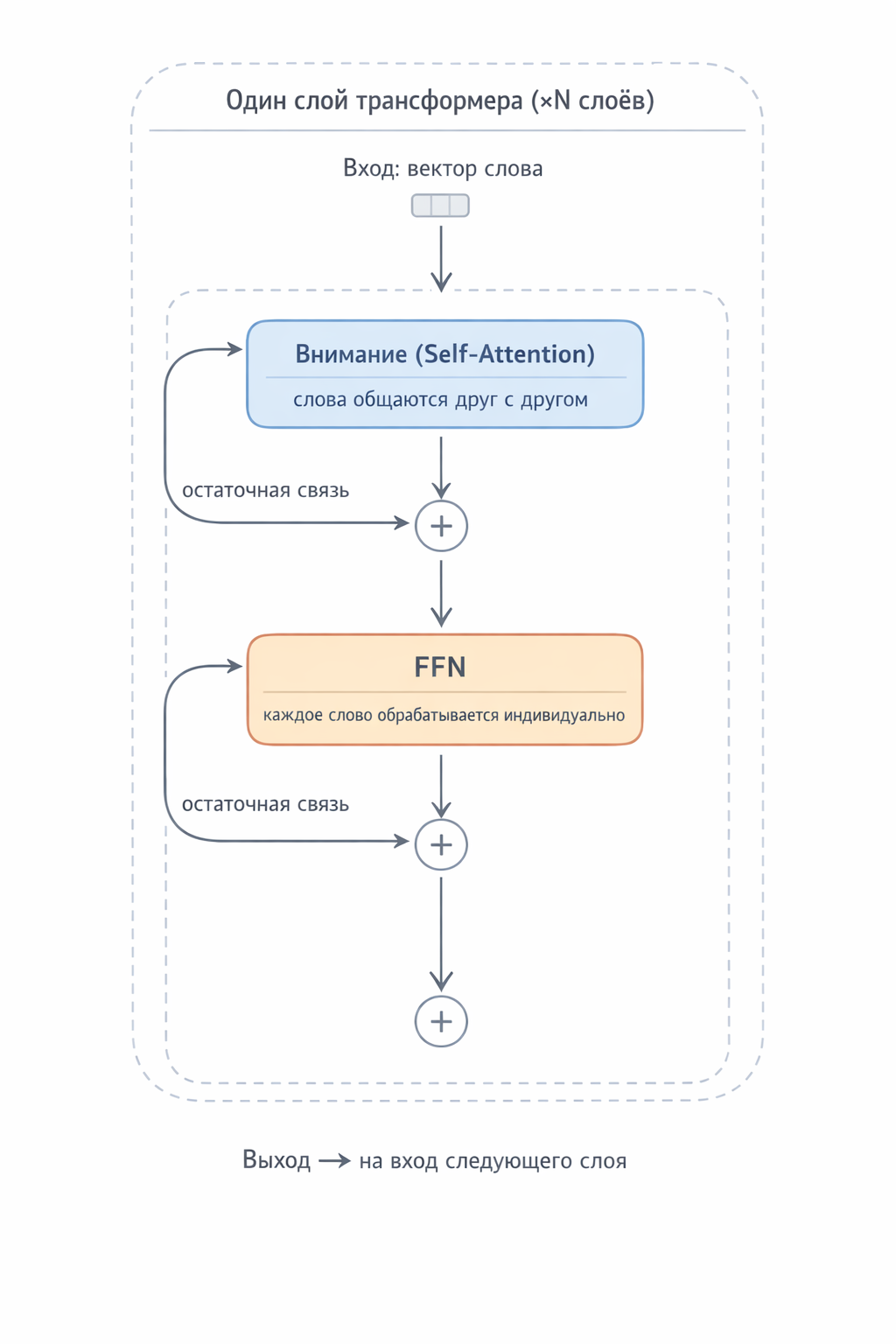
Рис. 4. Один слой трансформера: блок Внимания (коллективная операция — слова обмениваются информацией), затем FFN (индивидуальная операция — каждое слово обращается к «библиотеке знаний»). Остаточные связи сохраняют исходную информацию.
Таких чередующихся попарно слоёв много — больше сотни в современных моделях. Без FFN трансформер — это совещание, после которого никто не идёт работать.
Устройство FFN: двухслойная нейросеть
FFN — это простая нейросеть: всего два полносвязных слоя с функцией активации между ними. Ни свёрток, ни рекуррентности, ни внимания — тот самый перцептрон, описанный Яном Лекуном этак в 1960-х.
Вся механика FFN укладывается в три шага: расширить → отфильтровать → сжать.
Вектор слова (4096 чисел) поступает на вход. Первая матрица W₁ расширяет его в четыре раза — до 16 384 чисел. Это временное рабочее пространство: чем оно шире, тем больше разных «вопросов» модель может задать одновременно. Функция активации ReLU (простой алгоритм — если число отрицательное, заменить нулём; если положительное — оставить как есть) отсекает всё неактивное — из 16 384 нейронов на типичном слове откликается лишь 2–5%. Вторая матрица W₂ сжимает ответы активных нейронов обратно в 4096 чисел — тот же формат, с которым работает весь остальной трансформер.
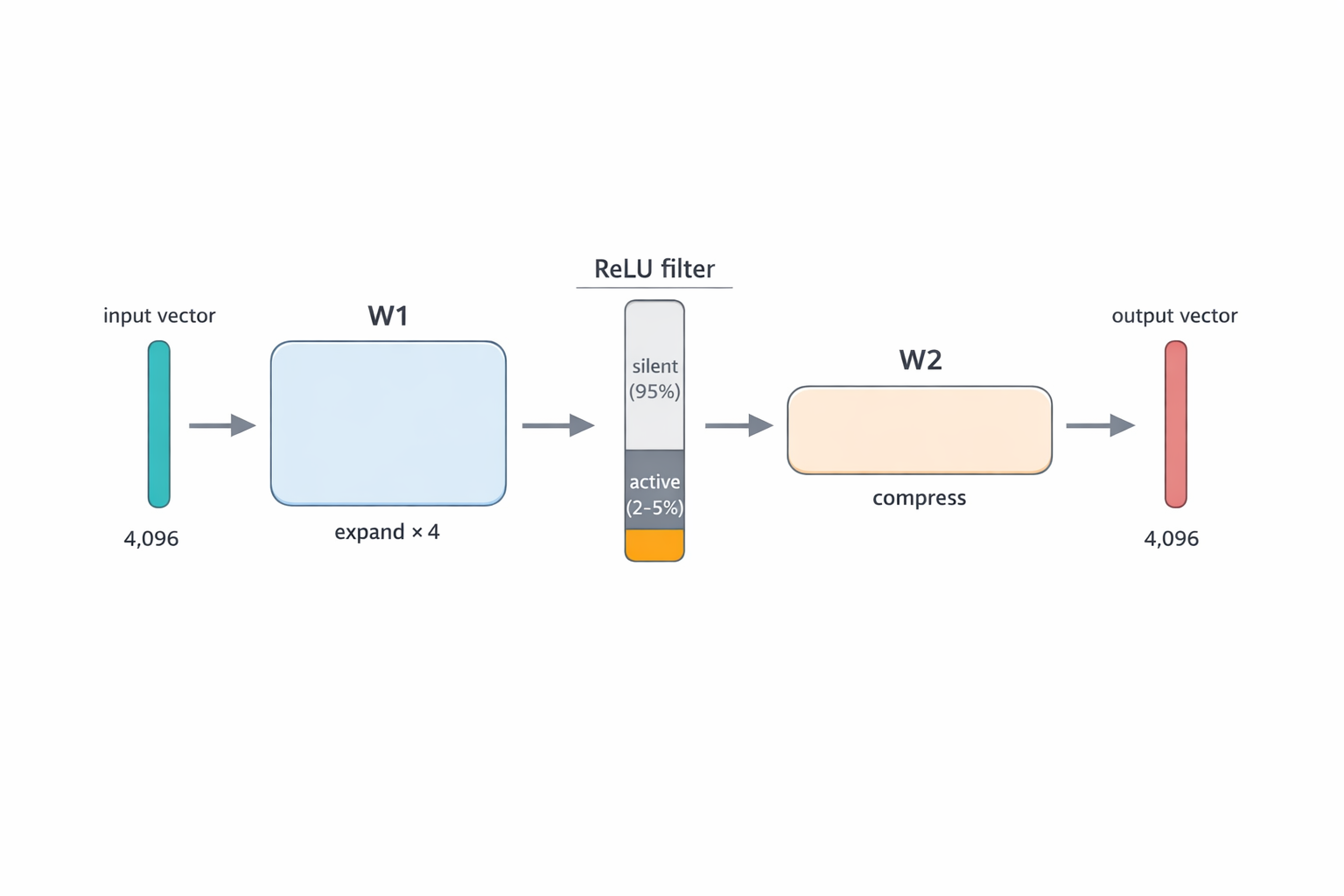
Рис. 5. Внутренняя архитектура FFN: входной слой (4096) → матрица W₁ расширяет в 4 раза → скрытый слой (16384 нейронов, ReLU отключает неактивные) → матрица W₂ сжимает обратно → выходной слой (4096).
Что такое матричное умножение (и зачем оно здесь)
Прежде чем разбирать три шага FFN, давайте разберёмся с матричным умножением. Не паникуем.
Вектор — это просто список чисел. Вектор слова в трансформере — это 4096 чисел, каждое из которых отвечает за какой-то аспект смысла. Упростим для примера до 4 чисел:
вектор слова «Минск» = [0.8, 0.1, 0.6, 0.3]
Что значат эти числа? Грубо говоря: 0.8 — «связано с географией», 0.1 — «связано с едой», 0.6 — «это главный город страны», 0.3 — «абстрактное понятие». (В реальности модель сама решает, что значит каждое число, но идея такая.)
Строка матрицы W₁ — это один нейрон-детектор. Он тоже список из 4 чисел — паттерн, который этот нейрон ищет:
нейрон «красивая столица» = [0.9, 0.0, 0.7, 0.0]
Этот нейрон «заряжен» на географию (0.9) и столичность (0.7), а еда и абстракции ему безразличны (0.0).
Скалярное произведение — это проверка: насколько вектор слова совпадает с паттерном нейрона? Берём каждую пару чисел, перемножаем и складываем:
0.8 × 0.9 + 0.1 × 0.0 + 0.6 × 0.7 + 0.3 × 0.0 = 0.72 + 0 + 0.42 + 0 = 1.14
Результат 1.14 — высокое число. Нейрон «красивая столица» сильно активировался на слово «Минск». И правда красивая!
А теперь другой нейрон — «глагол движения»:
нейрон «глагол движения» = [0.0, 0.0, 0.1, 0.9]
Скалярное произведение с «Минском»:
0.8 × 0.0 + 0.1 × 0.0 + 0.6 × 0.1 + 0.3 × 0.9 = 0 + 0 + 0.06 + 0.27 = 0.33
Результат 0.33 — слабый. Нейрон «глагол движения» почти не реагирует на «Минск». Тоже логично — Минск не глагол.
Вот и всё матричное умножение. Матрица W₁ — это стопка из 16384 таких нейронов-строк. Каждая строка — свой паттерн. Умножение вектора на матрицу — это одновременная проверка 16384 паттернов за один шаг. На выходе — 16384 чисел, каждое говорит: «насколько вход похож на мой паттерн».
Ключевая интуиция: матричное умножение — это не абстрактная математика. Это массовый параллельный поиск по базе паттернов. W₁ содержит 16 384 «вопросов», и каждый вопрос одновременно проверяется на входном векторе.
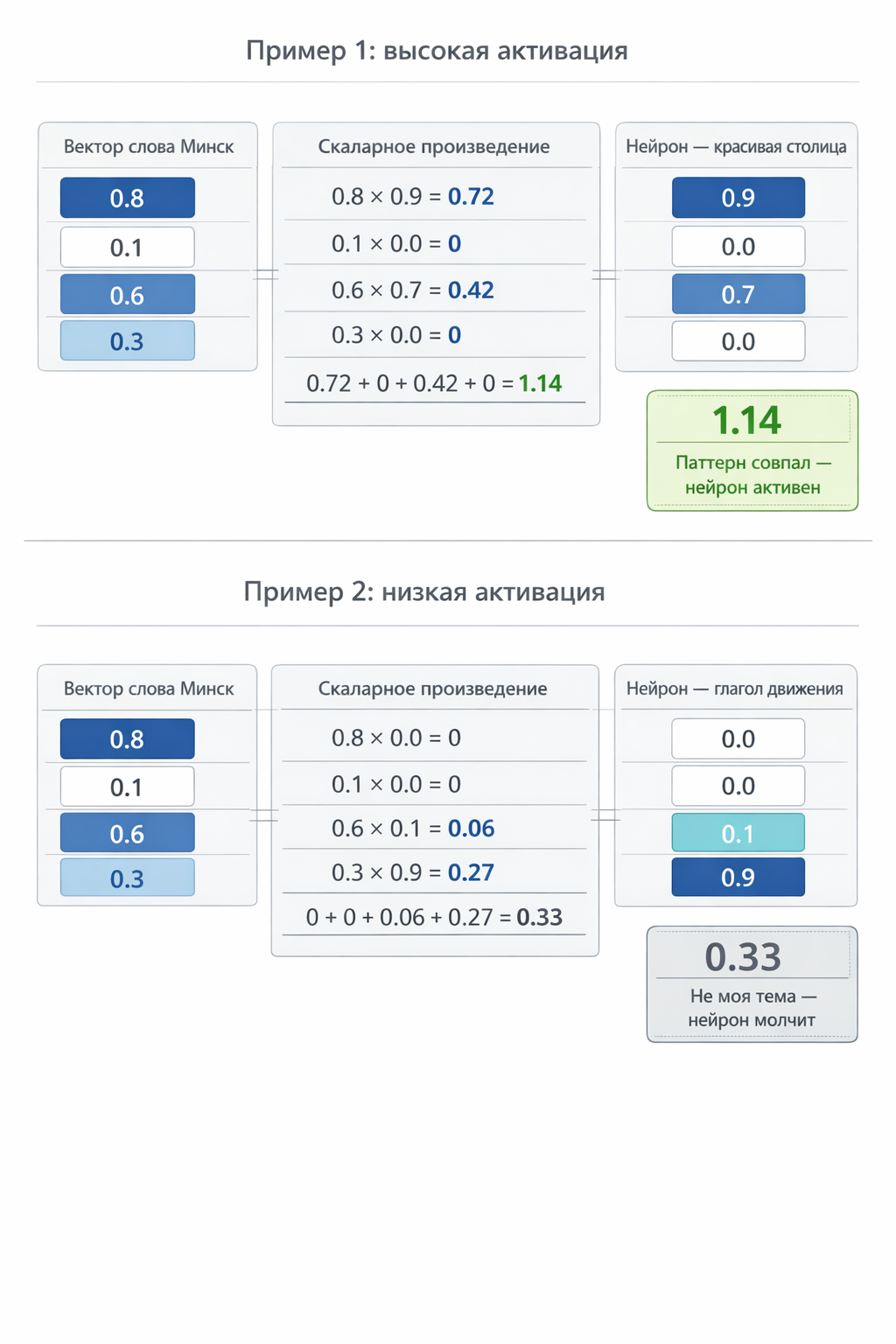
Рис. 6. Скалярное произведение — основа матричного умножения. Строка матрицы W₁ (паттерн нейрона) поэлементно умножается на вектор слова, результаты складываются. Высокий результат = «паттерн совпал», низкий = «не моя тема».
Нейрон
А давайте еще разберемся с тем что такое нейрон. Выше - строка “строка матрицы W₁ — это один нейрон-детектор”. Если точнее - то нейрон это скорее функция, содержащая этот самый вектор, смещение и функцию активации. Но в смысловом понимании нейрона - не как простой структуры данных, а с точки зрения феноменологии познания модели?
Я бы это определил как “атом смысла”. Но не в человеческом понимании (как слово в словаре), а в специфическом, «машинном» смысле. Разобьём на уровни, чтобы попытаться понять его смысловую сущность:
Нейрон — это элементарная единица абстракции. Это способ модели «вычленить» из хаоса данных одну конкретную грань реальности и дать ей имя (в виде активации). Как говорил Аристотель, «подлинное бытие — это деятельность». Нейрон не «есть» — он «случается» в момент активации. Но проблема в том, что нейроны часто многозначны. Один и тот же нейрон может реагировать и на «имена собственные», и на «слова после запятой». То есть его «смысл» — это не четкое определение, а сгусток корреляций. Как было у Шекли - «Иллюзорной сущности — иллюзорную монетку» (с) . Нейрон оперирует не объективным миром, а его тенями в векторном пространстве. Он не отражает реальность напрямую, он создает её статистический слепок.
Нейрон — фильтр реальности. Вопрос, который модель задает миру. Человеческий вопрос: «Где я?» Нейронный «вопрос»: «Насколько вектор входа совпадает с моим внутренним напряжением (весами)?» Смысл нейрона раскрывается только в отношении. Он не существует сам по себе. Он существует только как реакция. Сущность нейрона — это не объект, а событие. Это акт распознавания. Это не смысловая сущность в вакууме. Это координата в многомерном пространстве смыслов.
Нейрон — это элементарный акт различения. Это минимальная единица, которая говорит: «Вот это — немного больше похоже на то, чем на это». Его веса — это не «знания», а кристаллизованный опыт проверки этой гипотезы на миллионах примеров. Когда нейрон активируется, он не «вспоминает факт» — он говорит: «Моя гипотеза снова нашла подтверждение». Но без входящего сигнала этот механизм мертв. Опять вспоминая Шекли - «Не было различий, ибо некому было о них спрашивать». Без вопроса (входных данных) нейрон — лишь пустая форма. Смысл рождается только на стыке вопроса и ответа.
Как проходят данные: расширение → фильтрация → сжатие
Теперь, когда мы знаем, что матричное умножение — это «проверка паттернов», три шага FFN становятся понятными:
Шаг 1 — Расширение (W₁). Вектор слова (4096 чисел) умножается на матрицу W₁ (16384 строк × 4096 столбцов). Каждая строка — нейрон-детектор со своим паттерном. Результат — 16384 чисел, каждое показывает силу реакции одного нейрона. Это как одновременно задать 16384 вопросов: «Ты столица?», «Ты глагол?», «Ты про еду?»…
Зачем расширять из 4096 в 16384? Потому что 4096 вопросов — мало для хранения всех знаний модели. При 4096 нейронах один нейрон вынужден совмещать несколько тем: «Минск-столица» и «Минск-кулинария» были бы в одном ящике. При 16384 — каждая тема получает свой отдельный нейрон. Больше детекторов = точнее специализация.
Шаг 2 — Фильтрация (ReLU). После умножения на W₁ у нас 16 384 числа. Некоторые — большие положительные (нейрон «узнал» своё), некоторые — около нуля или отрицательные (нейрон «пожал плечами»). ReLU делает одно простое действие: max(0, z) — всё отрицательное превращает в ноль.
Почему именно так, а не, например, оставить маленькие значения? Потому что нам нужна чёткая граница между «нейрон активен» и «нейрон молчит». Слабый сигнал — это шум, не знание. ReLU говорит: либо ты уверен — либо молчи.
А теперь про семантику. Вспомним, что вектор слова — это координаты в смысловом пространстве. Слова с похожим смыслом имеют похожие векторы — они «указывают» в одну сторону пространства. Нейрон тоже хранит вектор-паттерн. Скалярное произведение — это угол между двумя векторами: если слово и нейрон «смотрят» в одну сторону, произведение большое и положительное → ReLU пропускает. Если нейрон настроен на совсем другую тему — произведение нулевое или отрицательное → ReLU обнуляет.
Итог: из 16 384 нейронов активны лишь 2–5% — те, чья «специальность» семантически близка к текущему слову. Для «Минска» в контексте «столица» — активируются нейроны про географию и политику, а нейроны про еду, программирование или спорт получают ноль.
Шаг 3 — Сжатие (W₂). Теперь нужно «упаковать» ответы активных нейронов обратно в рабочий формат 4096 чисел. Матрица W₂ (4096 строк × 16384 столбцов) делает обратную операцию: каждый столбец W₂ — это «рецепт», описывающий, как активный нейрон меняет выходной вектор. Активные нейроны вносят свой вклад, молчащие — нулевой.
Зачем сжимать обратно? Потому что вся остальная модель (внимание, следующий слой, финальное предсказание) работает с векторами размером 4096. 16384 — это временное рабочее пространство, как рабочий стол, на который вы раскладываете папки из шкафа. Поработали — сложили обратно в портфель (4096) и понесли на следующий этаж (следующий слой).
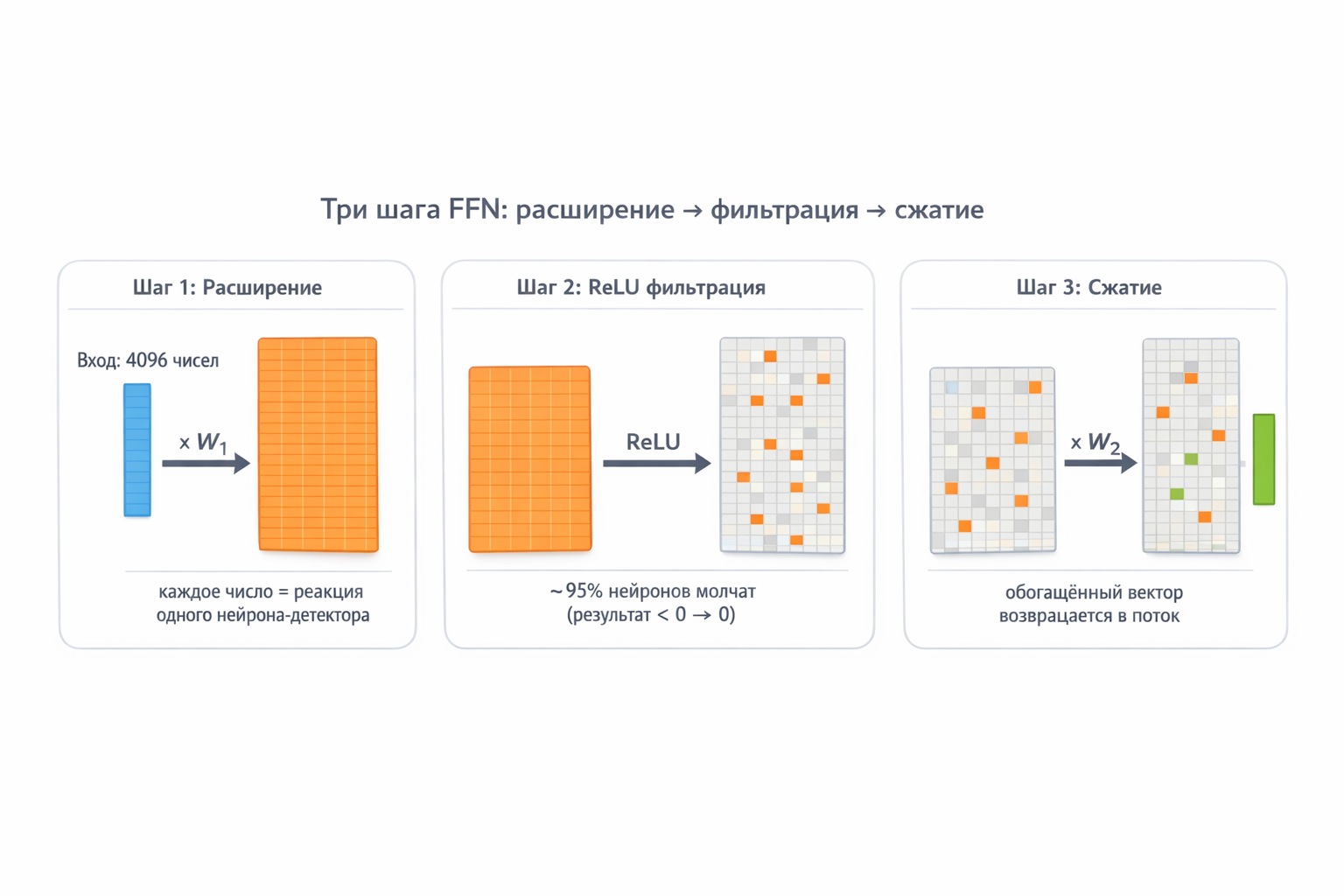
Рис. 7. Пошаговый проход через FFN: вектор слова (4096) → W₁ расширяет до 16384 нейронов-детекторов → ReLU отключает нерелевантные (95% замолкают) → W₂ сжимает активные ответы обратно в 4096.
Пример: слово «Минск» проходит через один слой
Фраза: «Минск — столица Беларуси».
Шаг 1 — Внимание. Слово «Минск» опрашивает все остальные слова и находит, что «столица» (вес 0.45) и «Беларуси» (0.30) для него важны. Вектор «Минска» обогащается контекстом — теперь он «знает», что речь о столице.
Шаг 2 — FFN. Обогащённый вектор попадает в FFN. Из 16384 нейронов активируются те, чьи паттерны совпали:
- Нейрон «красивые столицы» → добавляет: «→ Беларусь, широкие проспекты»
- Нейрон «славянские языки» → добавляет: «→ русский»
- Нейрон «послевоенная архитектура» → добавляет: «→ проспект Независимости»
- Нейроны «кулинария», «программирование», «глагольные времена» → молчат
На выходе вектор «Минска» содержит не только контекст от внимания, но и знания: столица Беларуси, Восточная Европа, русский язык.
Ключевой момент: FFN работает только со словом «Минск» — не смотрит на «столица» или «Беларуси». Контекст слово уже получило на этапе внимания. FFN только достаёт знания из своей памяти.
FFN на разных слоях: от грамматики до фактов
FFN на каждом слое делает разную работу. В моём понимании картина примерно такая:
Нижние слои (1–8) — базовая обработка языка. Нейроны реагируют на грамматические паттерны: части речи, род, время, падеж. Возьмём омоним, например «коса», — на нижних слоях это просто «существительное, женский род, может быть многозначным» — без понимания, это инструмент для кошения травы или причёска.
Средние слои (9–20) — семантика и разрешение многозначности. Если рядом с «коса» стоят «трава» и «поле» — активируются нейроны про сельское хозяйство. Если «волосы» и «барбер» — нейроны про причёску. Одно слово получает разные «добавки» в зависимости от контекста.
Верхние слои (21–32+) — факты и рассуждения. Нейроны хранят конкретные знания: «Минск → Беларусь», «Москва → Россия». Здесь же работает абстрактная логика: стиль, тон, структура аргументации.
Фраза: «Она бежала по тёмной улице, потому что за ней кто-то шёл»
| Слой 3 (нижний) | Слой 25 (верхний) | |
|---|---|---|
| «бежала» | глагол, прош. время, жен. род, движение | страх, опасность, побег, погоня |
| «тёмной» | прилагательное, предл. падеж, ж.р. | опасность, ночь |
| «шёл» | глагол, прош. время, м.р., движение | преследование, угроза |
Нижний слой — «секретарь»: записывает грамматику. Верхний слой — «аналитик»: делает выводы.
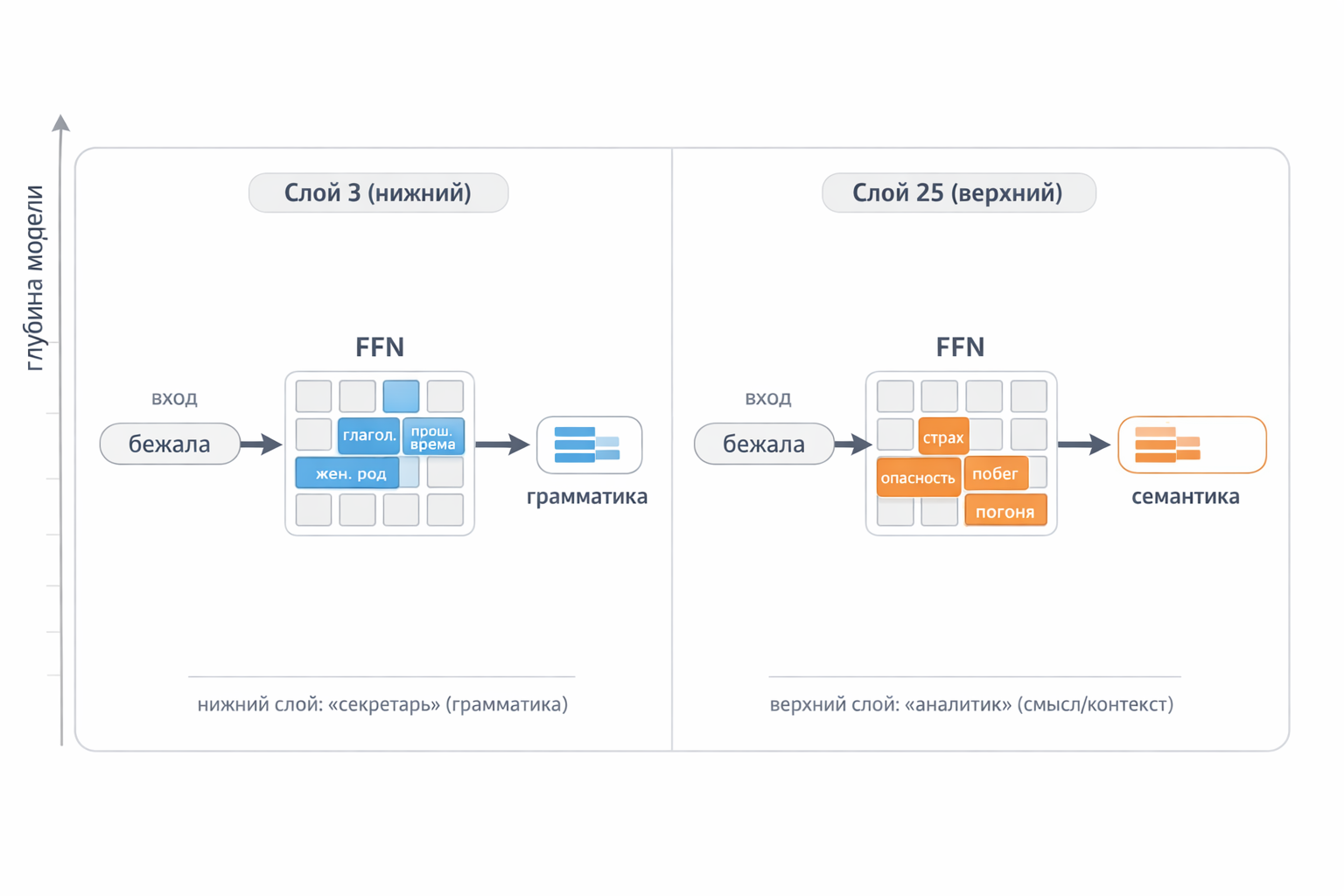
Рис. 8. На нижних слоях FFN выделяет грамматические признаки, на верхних — семантические. Одно и то же слово, но совершенно разная обработка.
Как FFN обучается: история одного нейрона
Как нейрон становится «специалистом»? Разберём на примере Нейрона №3847, который учится распознавать красивые столицы.
Шаг 1 — до обучения. Веса случайные. Модели показывают «Минск — столица ___», она отвечает неправильно: «Польши». Нейрон №3847 слабо активируется и никак не помогает.
Шаг 2 — коррекция ошибки. Правильный ответ — «Беларуси». Алгоритм backpropagation вычисляет: если бы нейрон сильнее реагировал на паттерн «Минск + столица», ошибка была бы меньше. Веса слегка корректируются.
Шаг 3 — тысячи примеров. Модель встречает «Минск — столица Беларуси», «Москва — столица России», «Скопье — столица Македонии» — нейрон усиливает реакцию на паттерн «[город] + столица». Встречает «Минск славится драниками» — здесь контекст другой, нейрон учится молчать без слова «столица».
Шаг 4 — специализация. После миллиардов примеров нейрон стал детектором: сильно активируется на «[город] + столица», молчит в остальных контекстах. Его выходные веса (W₂) настроены так, чтобы при активации «подсказывать» правильную страну.
Это происходит одновременно с 16384 нейронами в каждом из 120 слоёв. Никто не программировал «нейрон для столиц» — специализация возникает сама из процесса обучения.
Почему бывают галлюцинации? Нейрон выучил паттерн, а не таблицу фактов. Если подать «Вакандо — столица ___», нейрон активируется (паттерн совпал), и модель «уверенно» назовёт какую-то страну — хотя Вакандо не существует.
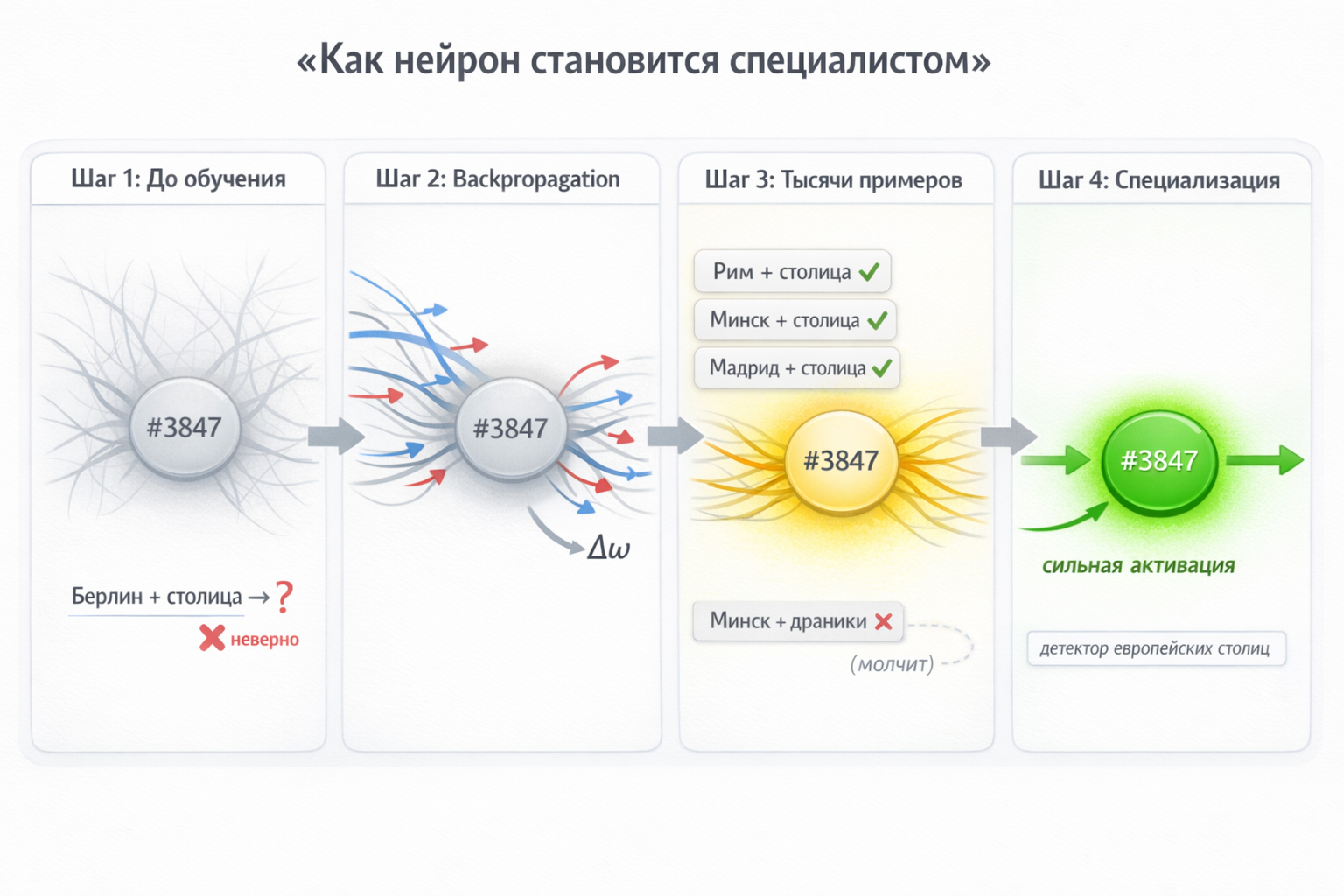
Рис. 9. Четыре этапа обучения: случайные веса → backpropagation корректирует ошибку → после тысяч примеров нейрон специализируется → становится «детектором столиц».
4. Скрытые состояния: путешествие вектора
Что такое скрытое состояние
Когда токен проходит через трансформер, его вектор непрерывно трансформируется на каждом слое. Эти промежуточные векторы называются скрытыми состояниями (hidden states).
- Слой 0 (эмбеддинг): вектор содержит лишь базовое значение слова — «кошка» = примерное представление о кошках.
- Слой 4: вектор уже «знает», что это конкретная кошка из контекста — «та самая кошка, которая сидела на крыше».
- Слой 32: вектор несёт глубокое понимание — роль слова в предложении, связи с другими словами, эмоциональный тон.
Остаточные связи: Memento
Важный механизм — остаточные связи (residual connections). После каждого блока (внимание, FFN) результат прибавляется к входу, а не заменяет его:
выход = вход + результат_блока
Это значит, что исходная информация никогда не теряется полностью — каждый слой лишь добавляет новые «слои смысла» поверх старых. Без этого механизма глубокие сети не смогли бы обучаться — информация затухала бы на пути через десятки слоёв.
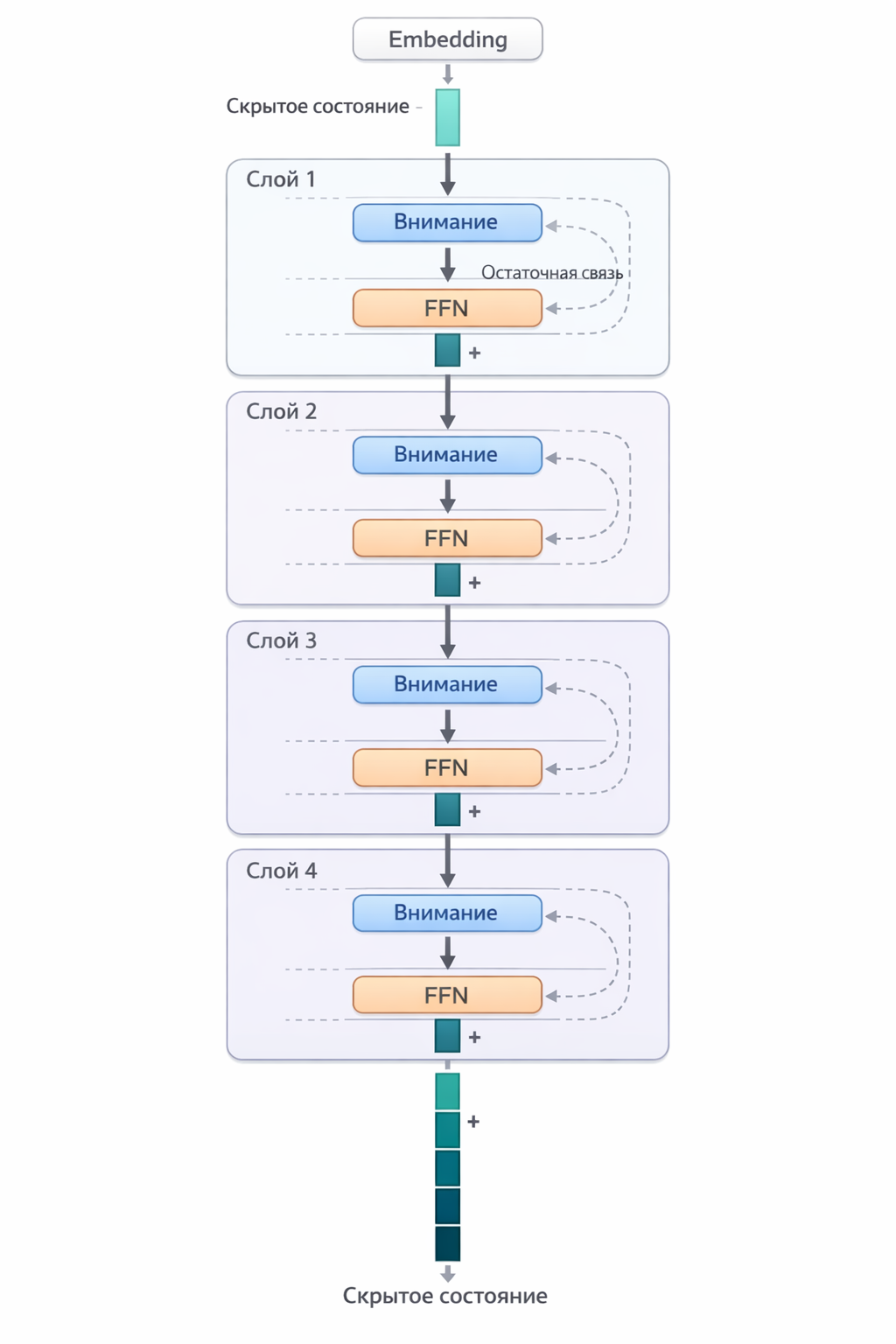
Рис. 10. Путь вектора через слои трансформера с остаточными связями
5. KV-кеш: ускорение генерации текста
Как формируется KV-кеш
Вернёмся к механизму внимания. Каждый токен на каждом слое трансформера порождает три вектора:
- Query (Q) — «что ищет этот токен?»
- Key (K) — «что предлагает этот токен?»
- Value (V) — «что он передаёт, если его выбрали?»
Подробнее про Q, K, V — в предыдущей статье.
При генерации текста модель работает пошагово: сначала генерирует первый токен, потом второй, и так далее. Чтобы сгенерировать каждый новый токен, механизм внимания должен сравнить его Query со всеми предыдущими Key и собрать Value — то есть «прочитать» весь уже написанный текст заново. Без оптимизации — это заново пересчитывать K и V для каждого токена на каждом шаге.
Решение простое: K и V вычислить один раз — и сохранить. Так и работает KV-кеш. Каждый раз, когда токен проходит через слой, его Key и Value записываются в кеш. При генерации следующего токена нужно вычислить только Query для нового токена, а ключи и значения всех предыдущих берутся из кеша напрямую.
Две фазы обработки промпта:
- Prefill (предзаполнение) — пользователь отправляет промпт. Модель обрабатывает все токены параллельно, заодно вычисляя и сохраняя K и V в кеш для каждого слоя.
- Decode (декодирование) — генерация по одному токену. Каждый новый токен добавляет свою пару K, V в кеш и использует все предыдущие для вычисления внимания.
Цена KV-кеша — память
KV-кеш хранится в GPU-памяти и растёт с каждым токеном. Чтобы понять масштаб: в модели типа LLaMA-3 70B с 80 слоями один токен порождает 80 пар векторов K и V по 8192 чисел каждый — это около 10 МБ на один токен (в float16). При контексте 128 000 токенов кеш занимает более 100 ГБ — больше, чем сама модель. Поэтому длина контекстного окна ограничена не математикой, а объёмом GPU-памяти.
Prefix caching: «я это уже считал»
Типичный сценарий в продакшне — тысячи запросов к одной модели. Большинство начинаются одинаково: один и тот же системный промпт («Ты — ассистент-юрист, отвечай формально…»), или одна и та же база знаний, загруженная в контекст. Соответственно, зачем каждый раз считать K и V для этих токенов заново?
Поэтому кешируем KV не только внутри одного запроса, но и между запросами. Именно так работает Automatic Prefix Caching в vLLM — одном из самых популярных движков для развёртывания LLM.
Механизм хеширования работает следующим образом. KV-кеш нарезается на блоки фиксированного размера — например, по 16 токенов. Каждый блок хешируется по двум составляющим: токены самого блока и хеш родительского блока (то есть всего предшествующего текста). Это создаёт цепочку хешей: блок 2 зависит от блока 1, который зависит от блока 0.
Когда приходит новый запрос, vLLM хеширует все блоки промпта и ищет совпадения в таблице кеша. Если первые 12 блоков из 15 найдены — они берутся из кеша, prefill выполняется только для последних 3. Cache hit означает: не нужно прогонять токены через все 80 слоёв модели — вычисления пропущены полностью.
Блоки, которые давно не использовались, вытесняются по принципу LRU (Least Recently Used — последний использованный удаляется первым). Кешируются только полные блоки — неполный последний блок не хешируется, пока не заполнится.
Итог: при повторяющихся префиксах время ответа сокращается в разы, а GPU занимается только тем, чего ещё не считал.
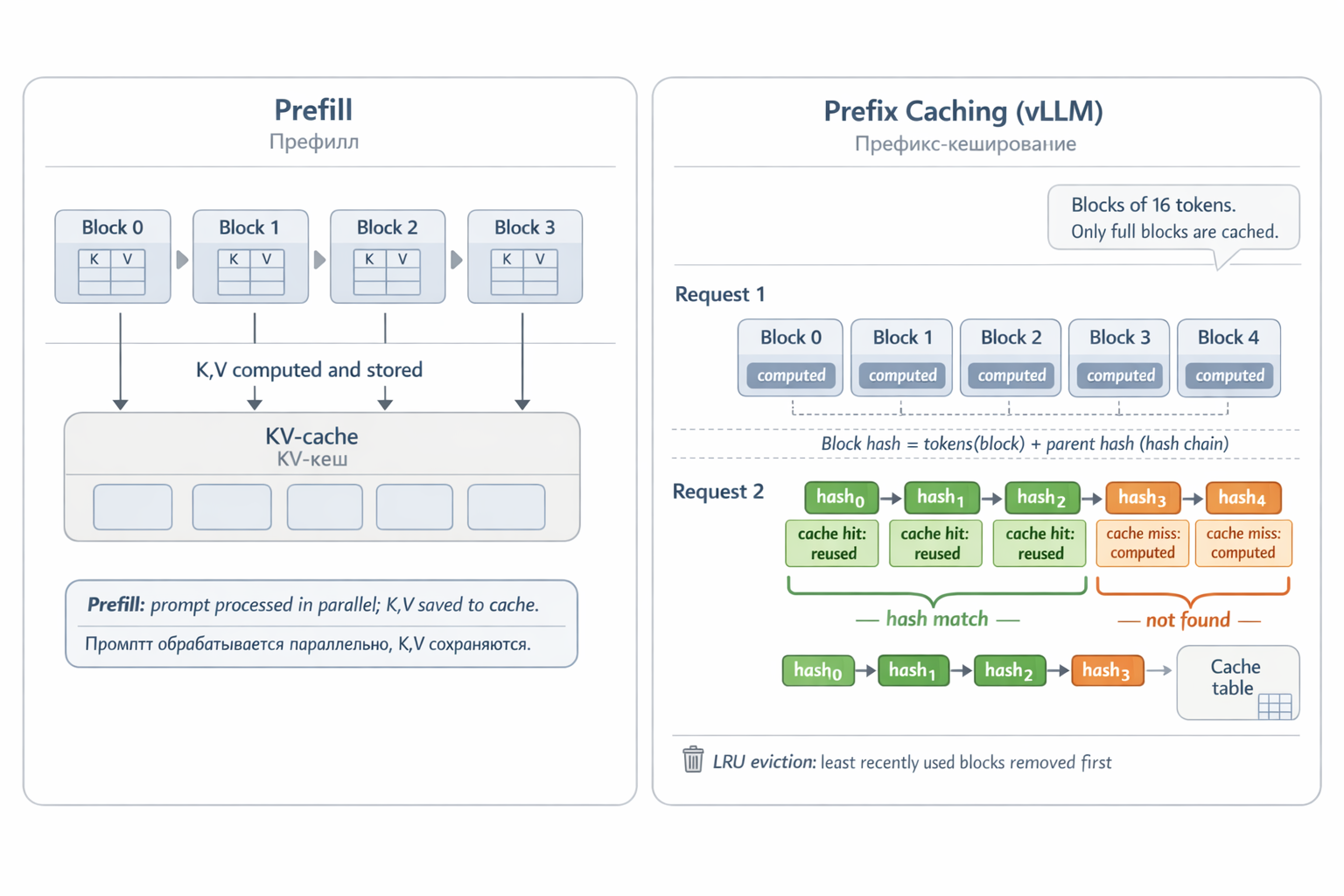
Рис. 11. KV-кеш: prefill вычисляет K,V для каждого токена. При prefix caching новый запрос с тем же началом находит первые блоки в кеше по хешу — и пропускает их вычисление.
6. Как всё связано вместе
Подведём итог и посмотрим на полную картину — от ввода текста до генерации ответа:
Токенизация — текст разбивается на токены, каждый получает числовой вектор (эмбеддинг) + позиционную информацию.
Проход через слои — вектор каждого токена проходит через N слоёв, каждый из которых:
- Внимание: токены обмениваются информацией (Query-Key-Value).
- FFN: каждый токен обогащается знаниями из «памяти» модели.
- Остаточные связи: исходная информация сохраняется.
Предсказание — вектор последнего токена проходит через финальный линейный слой → получается распределение вероятностей над всем словарём → выбирается следующее слово.
KV-кеш — при генерации текста ключи и значения сохраняются, чтобы не пересчитывать всё заново для каждого нового слова.
Повтор — шаги 2–4 повторяются для каждого нового токена, пока модель не сгенерирует ответ целиком.
Такие дела (с) Курт Воннегут «Бойня № 5»
Таким образом, улавливаем идею: позволить каждому слову свободно взаимодействовать с любым другим словом. Механизм внимания определяет, что важно; FFN-слои обогащают каждое слово знаниями; остаточные связи сохраняют информацию через десятки слоёв; а KV-кеш делает генерацию текста практически осуществимой.