«Учиться, учиться и учиться!» (с) В.И. Ленин
Зачем это все?
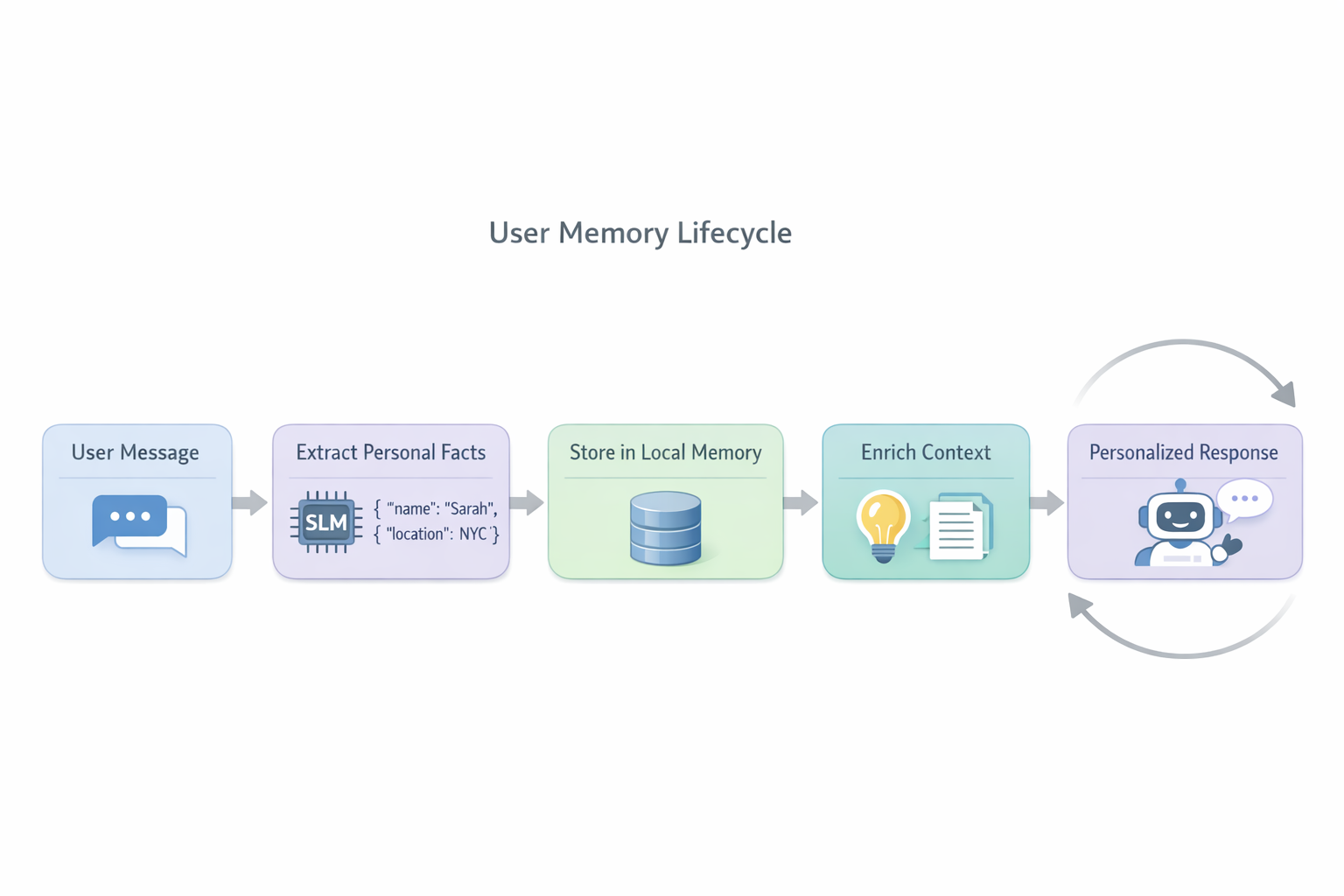
Итак — задача: реализовать ИИ-ассистента, использующего SLM (Small Language Model) для извлечения персонализированной информации о пользователе. Почему SLM? Ну, приватность — данные не уходят никому, экономия опять же. Детали нам не нужны тут — важно понять, возможно ли это вообще с приемлемым качеством, какие тернии нас ждут, кто виноват и что делать?
Поехали!
SLM
Глянем, что есть на Hugging Face — остановимся на свеженькой Qwen3.5-0.8B — вроде близко к тому, что нам нужно, 0.8B параметров, вполне. Теперь наша задача — выяснить, насколько модель умна для наших задач — а тут не всё просто. Наша цель в идеале что-то вроде Google Memory Bank. Кстати, Google выложил своё видение Context Engineering: Sessions and Memory и это очень интересно — особенно раздел Memory Generation: Extraction and Consolidation. Вкратце перечислим основные тезисы:
- Memory Generation — это ETL-пайплайн, а не просто «сохранить что сказал юзер». Google разделяет процесс на Extraction (извлечение фактов из диалога) и Consolidation (слияние, обновление и удаление фактов в хранилище). Без второго этапа память быстро захламляется дублями и противоречиями.
- Extraction работает лучше всего по схеме. Вместо свободного «запомни всё важное» модели дают конкретные категории/поля для извлечения (preferences, biographical facts и т.д.). Это резко повышает точность и предсказуемость результата.
- Consolidation — три операции: Merge, Delete, Create. Новый факт может обновить существующий, удалить устаревший или создать новую запись. Без этой логики модель будет одновременно помнить, что пользователь «любит вино» и «бросил пить».
- Memory Provenance определяет приоритет. Google вводит иерархию: явные инструкции пользователя > факты из диалога > выводы модели. При конфликте побеждает источник с более высоким приоритетом.
- Когда генерировать — отдельный вопрос. Можно после каждого сообщения, в конце сессии или по расписанию. У каждого подхода свои trade-offs по latency, стоимости и полноте. Google рекомендует end-of-session как разумный баланс.
- Качество генерации памяти — главная проблема. Дословно: «The quality of the generation stage is arguably the most critical component of the entire memory system».
Но от нашей маленькой SLM-модели всего этого ждать нереально — наша задача понять, что мы можем выжать по максимуму.
Начнем с тестов. Берем базовую модель Qwen 3.5 0.8B как есть и скармливаем ей какое-то количество тестовых сообщений. Типа «Я живу в Минске и работаю сварщиком» — а модель должна вернуть JSON с фактами: локация — Минск, профессия — сварщик.
В измерениях у нас три главных числа:
- Precision (точность) — из всего, что модель извлекла, сколько реально правильного? Если модель нашла 10 фактов, а правильных из них 5 — precision = 50%. Грубо говоря, это про «не выдумывает ли модель лишнего».
- Recall (полнота) — из всех фактов, которые БЫЛИ в тексте, сколько модель нашла? Если в тексте было 10 фактов, а модель нашла 5 — recall = 50%. Это про «не пропускает ли модель важное».
- F1 — среднее гармоническое между precision и recall. Одно число, которое говорит «в целом норм или нет». F1 = 1.0 — идеал, F1 = 0 — полный провал.
И вот результаты базовой модели: F1 = 0.49. Precision 0.46, Recall 0.53. То есть модель из коробки ловит примерно половину фактов, и при этом половина того, что она «находит», — мусор. Не очень. С другой стороны, модель хотя бы понимает задачу и выдает валидный JSON в 100% случаев. Значит потенциал есть.
Но пришлось столкнуться с большой проблемой галлюцинации модели. Это когда модель выдумывает факты, которых нет. Спрашиваешь «какая сегодня погода?» — а она тебе: «пользователь интересуется метеорологией». Просишь «переведи на французский» — получаешь: «пользователь знает французский». То есть никаких личных фактов в сообщении не было — а модель просто их выдумала. По моим тестам базовая модель нагаллюцинировала ложные факты в ~92% тестовых кейсов. А из пустых кейсов (где правильный ответ — пустой список) модель корректно вернула пустоту только в 78% случаев — в остальных 22% придумала факты из воздуха. Это, конечно, никуда не годится.
Значит, попробую дообучить модель делать то, что мне нужно.
Немножко теории
Тут немного погрузимся в детали — как именно мы дообучаем модель. Как вы все знаете, обучение сводится по сути к обновлению весов тензоров модели. Но весов этих много — и вот есть такая штука, как LoRA (Low-Rank Adaptation).
Представим конкретно. В каждом слое трансформера есть матрица весов W размером, скажем, 4096 × 4096 — это 16 миллионов чисел. При обычном fine-tuning мы обновляем их все. Это дорого, нудно, и для каждой задачи нужна полная копия модели.
Идея LoRA: когда мы дообучаем модель, изменения весов ΔW на практике затрагивают лишь малую часть всего пространства. Грубая аналогия: представьте огромную таблицу 4096 на 4096 — но реально значимых «направлений» в ней всего 16. Зачем тогда хранить и обновлять все 16 миллионов ячеек?
Вместо этого LoRA раскладывает поправку ΔW в произведение двух маленьких матриц:
ΔW = B × A
- A — матрица сжатия: берёт вход размерности 4096 и проецирует его в узкое пространство размерности r (у нас r = 16)
- B — матрица расширения: проецирует обратно из 16 в 4096
При работе входной вектор x идёт двумя путями — через оригинальные замороженные веса W и параллельно через нашу пару A и B. Результаты складываются:
h = W · x + B · A · x
Оригинальные веса W не трогаем вообще — учим только маленькие A и B.
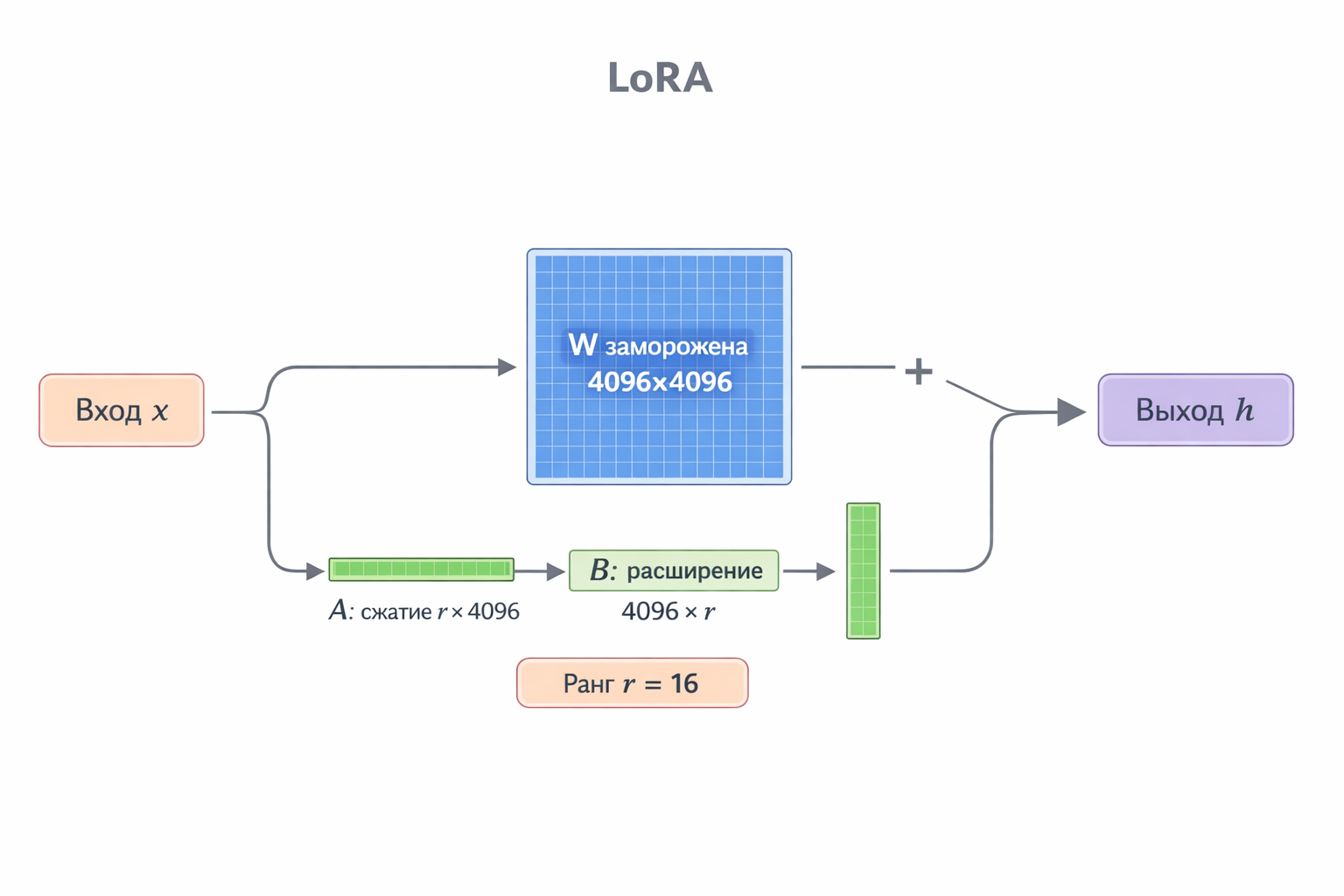
В итоге вместо 4096 × 4096 = 16 777 216 обучаемых чисел на слой, у нас (4096 × 16) + (16 × 4096) = 131 072 — в 128 раз меньше.
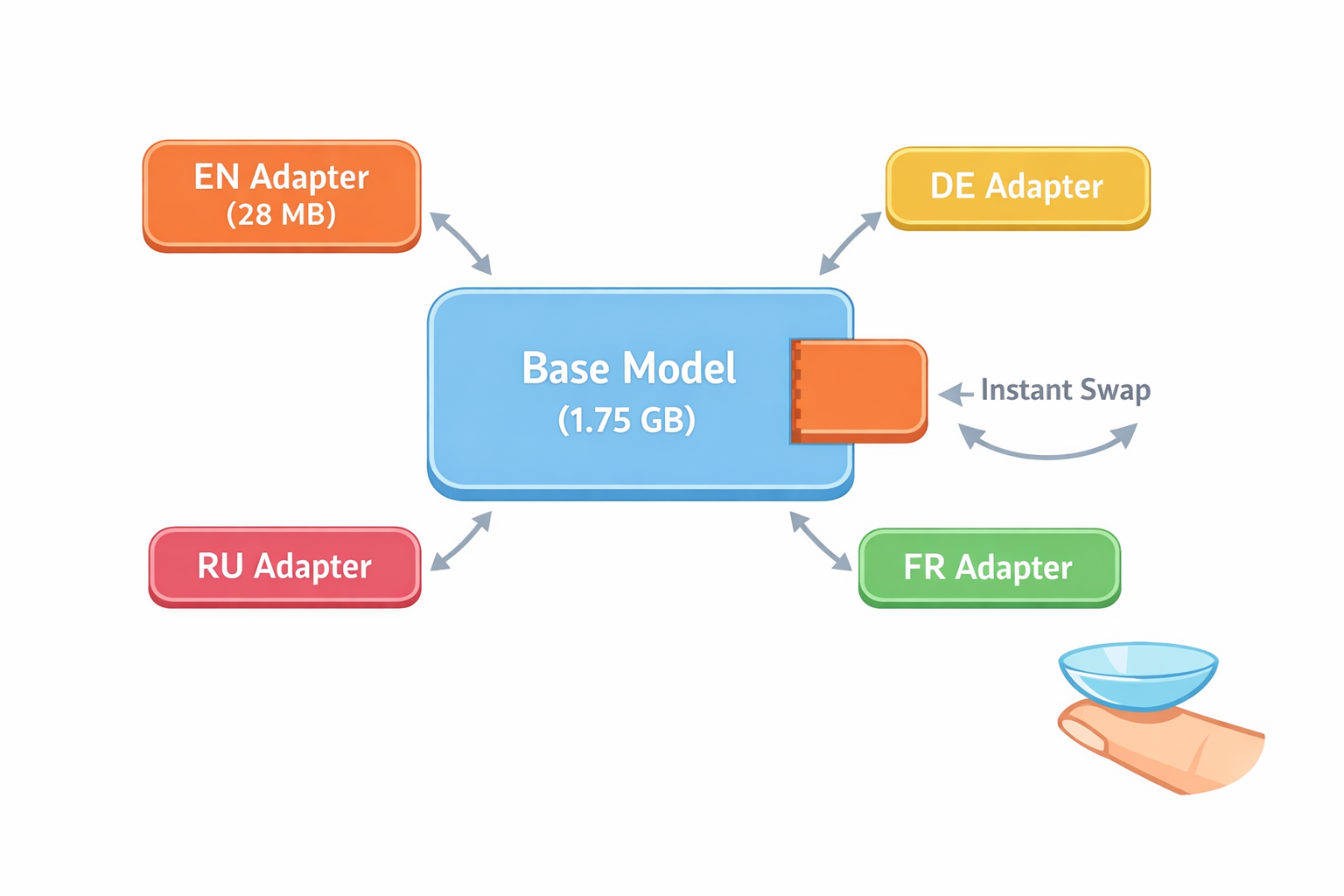
На практике: базовая модель весит ~1.75 ГБ, а LoRA-адаптер — всего ~28 МБ (~1.5% от модели). И важно — можно делать отдельные дообученные адаптеры под разные задачи, не трогая и не копируя базовую модель. Причём LoRA-адаптеры — формат универсальный: работает и с MLX (Apple Silicon), и с GGUF (llama.cpp / Ollama), и с обычным PyTorch. Адаптер — это просто набор матриц A и B, которые при загрузке применяются к базовой модели.
Данные для дообучения
Модели нужны примеры — «вот сообщение пользователя, вот какие факты из него надо извлечь». Чем больше и разнообразнее примеры, тем лучше модель обобщает. Руками их писать мы, конечно, не будем, поэтому просим LLM сгенерировать их.
Идея простая: мы описываем категории фактов (локация, диета, интересы, экспертиза, цели и т.д.), даём формат — и просим LLM сгенерировать разнообразные примеры сообщений с правильными ответами. Также нам нужны и «пустые» примеры, то есть не содержащие фактов — чтобы избавиться от галлюцинаций, описанных выше.
Формат обучающих данных — стандартный chat-format для MLX LoRA. Каждый пример — это диалог из трёх сообщений:
| |
Системный промпт одинаковый для всех примеров — описывает категории и правила извлечения. Пользовательское сообщение — вход. Ответ ассистента — эталонный JSON с фактами. Модель учится воспроизводить именно такие ответы.
А как оценивать качество? Нас же интересует семантическое совпадение, а не точность формулировок. Тут тоже используем LLM — подход LLM-как-судья. Берём наши тестовые датасеты (не пересекающиеся с обучающими данными), прогоняем через нашу модель, а затем при помощи мощной ЛЛМ сравниваем извлечённые факты с эталонными — то есть семантическое соответствие.
Первая итерация
Итак, датасет есть — запускаем обучение. Но сначала разберёмся с терминологией:
Итерация (training step) — это один шаг обучения: модель берёт один пример из датасета, считает ошибку и обновляет веса. При batch_size=1 одна итерация = один пример.
Эпоха (epoch) — это один полный проход по всему датасету. Если в train split ~1000 примеров и batch_size=1, то одна эпоха = ~1000 итераций.
Сколько учить — вопрос баланса. Слишком мало — модель не успеет ничего выучить. Слишком много — переобучится, то есть выучит наизусть обучающие примеры и не сможет работать с новыми данными. А нам надо в идеале научить модель обобщать.
Первая попытка: запустили на 200 итераций (~28% эпохи) — F1 = 0.52. Чуть-чуть лучше, но разница в пределах погрешности. При этом галлюцинации на пустых кейсах подтянулись — EmptyAcc вырос с 78% до 86%. То есть модель стала чуть реже выдумывать факты из воздуха, но в целом прибавка невелика.
Стало понятно, что нужно серьёзно дорабатывать и обучающие данные, и саму конфигурацию обучения. Покрутил learning rate, увеличил количество примеров, поднял число итераций до 500. Следующие попытки дали:
| Попытка | Итераций | F1 | Precision | Recall | EmptyAcc |
|---|---|---|---|---|---|
| Base | — | 0.49 | 0.46 | 0.53 | 78% |
| #1 | 200 | 0.52 | 0.49 | 0.55 | 86% |
| #2 | 500 | 0.78 | 0.76 | 0.80 | 86% |
| #3 | 500 | 0.80 | 0.77 | 0.84 | 86% |
| #4 | 500 | 0.80 | 0.83 | 0.78 | 100% |
Ключевой прорыв — итерация #4: EmptyAcc = 100%, то есть модель полностью перестала галлюцинировать на пустых кейсах. Если личных фактов нет — она честно возвращает пустой список. А F1 вырос с 0.49 до 0.80 — это серьёзный результат для модели в 0.8B параметров.
Но обнаружилась и ограниченность маленькой модели. Модель мультиязычна — но при попытке научить её работать с user memory на разных языках качество тут же просело по всем направлениям. Модели не хватает ёмкости, чтобы одновременно хорошо извлекать факты на разных языках. Как понимаю, это из-за размера модели. Вывод — дообучить мы можем на что-то одно.
Ладно — тогда учим модель извлекать факты только на английском. А пользовательские сообщения на других языках предварительно переводим на английский перед подачей в SLM. Так и храним.
Ну или вариант — можно дообучать под конкретный язык и получать отдельный LoRA-адаптер, их, кстати, можно подменять на лету. Что-то вроде плагинов.
Попробовал дообучить на испанском — и сразу показал F1 = 0.90 на испанских тестах. Но для своей задачи я особо смысла в таком подходе не вижу — так что это для справки больше.
Выводы
Итак, что мы выяснили. SLM на 0.8B параметров можно научить извлекать персональные факты из сообщений — и делать это более-менее. F1 с 0.49 до 0.80, галлюцинации с 22% до нуля. Для модели, которая весит меньше двух гигабайт — это вполне себе результат. Кроме того, её можно квантизировать — уменьшить ещё (у нас так-то bf16-версия). Но это ещё нужно протестировать, насколько упадёт качество на Q8, например.
Итак:
- Данные решают всё. Не архитектура, не гиперпараметры — а именно качество и разнообразие обучающих примеров. Первые итерации с плохими данными давали околонулевой прирост. Как только добавили больше «хитрых» пустых примеров (сарказм, негации, упоминания чужих фактов, или сослагательное наклонение), разнообразили implicit-кейсы и подкрутили learning rate с cosine decay — метрики скакнули с 0.52 до 0.78 за одну попытку.
- Маленькая модель — одна задача. Мультиязычность — не для 0.8B. Модель просто не вмещает достаточно знаний, чтобы одинаково хорошо работать на нескольких языках. Решение — один язык для извлечения, перевод на входе.
- LoRA — мощная штука. 28 МБ адаптер вместо полной копии модели на 1.75 ГБ. Можно держать отдельные адаптеры под разные задачи и языки, менять их на лету.
- LLM-as-judge. Семантическая оценка через большую LLM — единственный, наверное, способ мерить качество извлечения фактов.
- Пустые примеры. Без них модель галлюцинирует в 22% случаев. С ними — 0%. Модель должна уметь говорить «тут ничего нет» так же уверенно, как извлекать факты.