Эмбеддинги, внимание, FNN и все что вы хотели знать, но боялись спросить
Вступление
Сим я пытаюсь начать цикл статей, посвященных LLM (большим языковым моделям), нейросетям и всему, что рядом с аббревиатурой AI. Цели написания этих статей, конечно же, шкурные, ибо сам относительно недавно начал погружаться в эти темы и столкнулся с тем, что вроде бы и масса информации, и статей, и документов, написанных мелким шрифтом с заумными диаграммами и формулами, читая которые, заканчивая абзац, забываешь, о чем был предыдущий. Поэтому здесь я буду пробовать описать суть предметной области на концептуальном уровне - а посему обещаю избегать по максимуму математических формул и мудреных графиков, видя которые, читатель неизбежно ловит себя на желании закрыть вкладку браузера и посетить ближайший винно-водочный магазин. Так что - нет формулам (кроме самых простых), нет заумности, нет претензий выглядеть умнее, чем я есть. Эти статьи должна понять ваша бабушка, и если это не получилось - значит, я с поставленной задачей не справился.
Итак, эмбеддинги
Это очень хорошее слово - дабы выглядеть солидно, не забывайте вставить это слово в любом контексте, когда разговор заходит в область обсуждения AI. Шансы, что кто-то попросит вас уточнить, что это такое, и начнет задавать уточняющие вопросы, - мизерные, однако авторитет в глазах окружающих как минимум не упадет, да и кто захочет вопросами выдать свою дремучесть? Тем не менее, учитывая, что скорее всего вам скоро придется ходить по собеседованиям опять, - попробуем все же разобраться в сути явления на высоком абстрактном уровне.
Возьмем слово “кот”. Возьмем абстрактную, но обученную LLM-модель. Где-то в глубинах своих матриц-словарей она содержит это слово. Выглядит это примерно так:
| Слово | Вектор |
|---|---|
| Кот | [0.2, -1.3, 3.4, 5.6…] |
Так вот - что значит этот вектор? Эти цифры? А эти цифры - это координаты кота в смысловых измерениях.
Но как так - откуда у бездушной машины может быть понятие смыслового измерения? Правильно - не может. Но они есть. Откуда они взялись? А как результат обучения модели на информации, сгенерированной человечеством и до которой модель смогла дотянуться на этапе обучения. (Кому нужны подробности - Hugging Face Space). Но о подробностях обучения поговорим в следующих статьях.
Давайте предположим, что некое внеземное существо просит вас объяснить - что такое кот? Как вы это сделаете? Очевидно - попытаетесь пройтись по признакам:
- Кот? Ну, небольшой такой (относительно чего? Вируса? Бактерии? Синего кита? Нам нужна шкала измерения - пусть от 0 до 10)
- Это пушистый он (Насколько? Опять нужна шкала. А если сфинкс?)
- Короче, еще мяукает (Частотные характеристики? Форма спектра?)
- Он вполне разумен (Опять же - шкала разумности, как мы ее понимаем?)
На этапе обучения модель анализировала слова, которые часто встречались рядом со словом “кот”, и на основе этих данных вычисляла его характеристики. Например, рядом со словом “кот” часто встречались описания вроде “пушистый”, “небольшой”, “ловит мышей” и другие. Именно таким образом формируются координаты слова в многомерном пространстве признаков.
Другими словами, модель не оперирует признаками (смысловыми характеристиками) в человеческом понимании, а лишь выявляет статистические закономерности в тексте. Так могут выделиться, например, измерения, связанные с размером, поведенческими характеристиками или степенью разумности, даже если последнее не является буквальным.
Если упростить многомерное пространство до двух измерений, можно представить, где окажутся координаты “кота” относительно других сущностей:
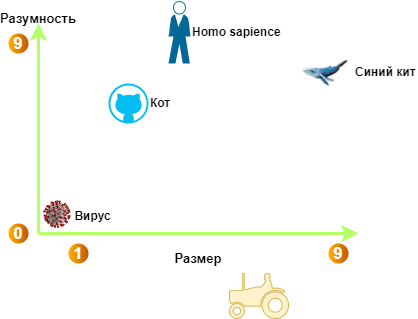
Смысловые координаты слов в пространстве одушевленности и размера
Итак - кот вполне разумен и размера небольшого. Для сравнения указаны другие представители нашей фауны и даже трактор - как некая противоположность смыслового значения кота: большой и неразумный. Конечно, это безумное упрощение, ибо в современных моделях таких смысловых измерений - до 2024 и больше. То есть это могут быть еще такие измерения, как:
- Физические характеристики
- Размер
- Вес
- Форма
- Цвет
- Поведенческие характеристики
- Разумность
- Активность
- Опасность
- Социальность
- Функциональные и ролевые признаки
- Полезность
- Одомашненность
- Эмоциональная окраска
- Временная принадлежность
- …
Чтобы упростить это представление, можно представить себе трехмерное пространство, где каждая галактика — это смысловое пространство. В этом пространстве каждая звезда представляет собой слово, а её координаты определяют его смысловое положение. Например, где-то в этом пространстве будет звезда, названная “кот”. Рядом с ней могут находиться звезды с именами “собака”, “хомяк” и “мышь”, так как эти слова семантически близки друг к другу. А вот “акула” будет подальше - вроде как тоже животное царство, но в классе хрящевых рыб.
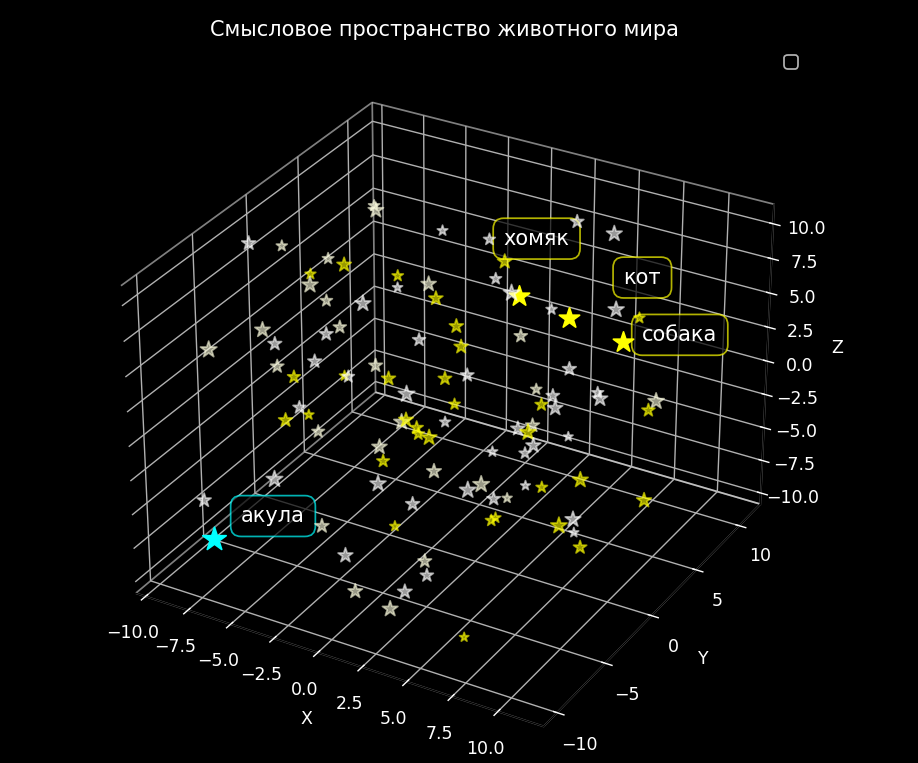
Координаты в смысловом пространстве
А теперь вспомним про теорию Мультиверса (да, эверетовская интерпретация, теория струн) и представим, что пространственных измерений куда больше трех - и каждое измерение определяет собственное смысловое пространство.
Ну а теперь, когда мы разобрались с эмбеддингами, перейдем к механизму “внимания”.
Attention, Attention! Или как модель понимает контекст
Итак - мы разобрались, что имеем некое многомерное смысловое пространство, но на уровне отдельных слов. А если речь идет об омонимах?
Представьте: вам говорит лицо мужского гендера “У меня новая коса”.
Что такое “коса”? Инструмент для косьбы травы или он проникся европейскими “ценностями”?
Чтобы понять, нужно учесть конктекст - например, что было сказано ранее - “Я на даче” - значит, скорее всего, речь о сельскохозяйственном инструменте. Ну или “Я вышел из барбера”- тогда дела печальны.
А как модели понять предложение и его смысл? Особенно если мы говорим о генеративной модели - что-нибудь в смысле:
Промпт: “Напиши рассказ о том, как мой ученый кот говорил, что он…"
Как модель понимает, чего я от нее хочу? Как понимает контекст всего текста? Вот для этого и придумали механизм “внимания” (attention mechanism).
Проблема, которую решает внимание
Нам нужно понять взаимосвязь слов в тексте. Например - что “ученый” - это характеристика кота, или “он” - опять же относится к коту. Конечно, мы не можем определить все такие связи со 100% уверенностью, но как минимум с высокой вероятностью.
Аналогия со следователем: как работают веса
Представим, что я следователь, расследующий отравление богатого человека. Естественно, я определяю круг подозреваемых - кто был рядом в момент преступления, кто имел доступ к потерпевшему и так далее.
Далее - я пытаюсь понять мотивы: кто-то жаждал наследства (алчность), кто-то испытывал личную неприязнь, кто-то боялся огласки каких-то секретов. Анализируя потенциальный мотив каждого подозреваемого, я как бы назначаю “вес” совокупности мотивов. У кого-то он больше, у кого-то меньше, а кому-то усопший был вообще безразличен.
Таким образом я сужаю круг подозреваемых, а кого-то вообще из него исключаю. Примерно то же самое делает механизм внимания - назначает “вес” каждому слову относительно всех других слов в тексте.
Три волшебные матрицы: Query, Key, Value
Представьте, что вы в библиотеке. У вас есть:
- Поисковый запрос (Query) - “покажите мне все про котов”
- Каталог (Key) - карточки всех книг с краткими описаниями
- Сами книги (Value) - содержимое, которое вы хотите получить
Механизм внимания работает похожим образом. Только вместо библиотеки у нас текст, а вместо книг - слова.
Шаг 1: Формируем Query (Запрос)
Берем слово “кот” из нашего текста. У него уже есть эмбеддинг - вектор координат в смысловом пространстве. Но нам нужно превратить его в запрос: “Какие слова в тексте помогут мне лучше понять этого кота?”
Для этого прогоняем эмбеддинг кота через специальную обучаемую матрицу Query. Получаем новый вектор - это наш “поисковый запрос”. Эта матрица обучена так, чтобы выделять именно те признаки, которые важны для поиска связей.
Шаг 2: Формируем Key (Ключи) для всех слов
Теперь берем ВСЕ слова из текста: “мой”, “ученый”, “кот”, “говорил”, “что”, “он”…
Для КАЖДОГО слова создаем его “ключ” - описание, по которому его можно найти. Прогоняем эмбеддинг каждого слова через матрицу Key. Получаем ключи для всех слов.
Шаг 3: Сравниваем Query с Key - ищем похожие
Теперь магия - сравниваем наш запрос про кота с ключом каждого слова. Модель вычисляет, насколько они похожи.
Чем выше оценка - тем сильнее связь. Например:
- “ученый” получает высокую оценку - это характеристика кота
- “говорил” получает среднюю оценку - действие кота
- “мой” получает низкую оценку - просто указывает владельца
Потом модель нормализует эти оценки - превращает их в веса от нуля до единицы, которые в сумме дают единицу. Например:
- вес “ученый” = 45%
- вес “говорил” = 35%
- вес “мой” = 15%
- вес остальных = 5%
Шаг 4: Получаем Value (Содержимое) и взвешиваем
Теперь для каждого слова берем его “содержимое” - прогоняем через третью матрицу Value. Она извлекает из каждого слова ту информацию, которую нужно передать дальше.
И создаем обогащенный эмбеддинг для слова “кот”, смешивая содержимое всех слов с учетом весов:
- берем 45% от “ученый”
- добавляем 35% от “говорил”
- добавляем 15% от “мой”
- добавляем 5% от остальных слов
Итак -теперь эмбеддинг слова “кот” содержит информацию о контексте: что он ученый и что он говорил.

Механизм внимания в действии
Почему три разные матрицы?
Казалось бы - зачем такие сложности? Почему не одна матрица?
- Query - выделяет “что ищем” (какие признаки важны для связей)
- Key - выделяет “чем можем быть полезны” (какую информацию несем)
- Value - содержит “что отдаем” (собственно данные)
Это как три разных взгляда на одно и то же слово. И все три матрицы обучаются - модель сама находит оптимальные значения.
Многоголовое внимание: когда одного мнения мало
Представьте ветеринарную клинику, куда принесли кота. Команда специалистов его осматривает: один проверяет общее состояние, другой слушает сердце, третий смотрит зубы, четвертый проверяет рефлексы. Каждый ветеринар видит свою часть картины.
Один механизм внимания - это как один ветеринар, который смотрит только с одной точки зрения. Он может заметить температуру, но пропустить что-то важное про зубы или лапы.
Много голов = много точек зрения
А что если у нас будет много специалистов, каждый смотрит на нашего кота по-своему?
- Голова 1: ищет связь “кто → что делает” → видит “кот → говорил”
- Голова 2: ищет связь “где → происходит” → может заметить предлоги
- Голова 3: ищет семантическую близость → “ученый” ↔ “говорил” (интеллект + речь)
- Голова 4: отслеживает кореференцию → понимает, что “он” = “кот”
И так далее - обычно в моделях 8-12 голов внимания.
Как это работает технически?
Очень просто - вместо одного набора матриц Query, Key, Value, у нас 8 наборов:
Голова 1: W_Q¹, W_K¹, W_V¹
Голова 2: W_Q², W_K², W_V²
...
Голова 8: W_Q⁸, W_K⁸, W_V⁸
Каждая голова:
- Независимо вычисляет свои Query, Key, Value
- Считает свое внимание
- Получает свой обогащенный вектор
Потом все выходы склеиваются в один длинный вектор и прогоняются через финальную матрицу.
Важный нюанс: размерность не меняется!
Если исходный эмбеддинг был размером 512, то и на выходе будет 512.
Как? Просто каждая голова работает в своем подпространстве:
- Общий размер: 512
- Голов: 8
- Размер каждой головы: 512 разделить на 8 = 64
То есть каждая голова смотрит на текст через свои 64 измерения из всех 512. Потом результаты склеиваются обратно: восемь кусочков по 64 снова дают 512.
Это как будто ты разделил свой мозг на 8 специализированных мини-мозгов, каждый эксперт в своем деле, а потом объединил их выводы.
Из чего состоит слой трансформера?
Теперь, когда мы разобрались с вниманием, давайте посмотрим на полную картину - что такое один слой трансформера?
Слой трансформера состоит из двух главных частей:
Часть 1: Механизм multi-head внимания
Это все, что мы только что обсудили:
- Берем эмбеддинги всех токенов
- Для каждой головы (например, 8 голов) вычисляем Q, K, V
- Считаем внимание
- Склеиваем результаты
- Применяем финальную матрицу
Важно: это не нейросеть, а просто линейные преобразования плюс взвешенная сумма. Никакой нелинейной активации здесь нет.
Часть 2: Feed-Forward Network (FFN) - а вот и нейросеть
После того как внимание обработало текст и выявило связи между словами, нужно дополнительно переварить эту информацию. Вот тут и появляется настоящая нейронная сеть.
FFN - это двухслойная полносвязная нейросеть. Она работает так:
- Сначала расширяет вектор (например, из 512 в 2048)
- Применяет нелинейную функцию активации (вот где “мозг”)
- Потом сужает обратно (из 2048 в 512)
Это применяется к каждому токену отдельно - независимо от других.
Зачем нужна FFN, если есть внимание?
Отличный вопрос! Вот зачем:
- Внимание отвечает за вопрос: “С кем общаться?” - находит связи между словами
- FFN отвечает за вопрос: “Что подумать?” - глубоко обрабатывает каждое слово по отдельности
Без FFN модель была бы чисто линейной (только умножения на матрицы), а значит - слабой. Именно ReLU в FFN дает трансформеру выразительную силу и способность моделировать сложные нелинейные зависимости.
Полный путь токена через один слой
Итак, что происходит с одним токеном, когда он проходит через слой трансформера:
-
Входной вектор размером 512
-
Механизм многоголового внимания:
- Вычисляем Query, Key, Value для всех голов
- Считаем взвешенную сумму
- Получаем обработанный вектор
-
Остаточное соединение и нормализация:
- Добавляем исходный вектор к обработанному
- Это помогает не потерять информацию
-
Нейросеть FFN:
- Расширяем вектор, применяем активацию, сужаем обратно
-
Снова остаточное соединение и нормализация
-
Выходной вектор идет в следующий слой
И так 12-24 раза (столько слоев обычно в современных моделях).
Визуализация слоя трансформера
Входной токен (512)
↓
┌─────────────────────────────────────┐
│ Multi-Head Attention │
│ │
│ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │Head 1│ │Head 2│ │Head 8│ │
│ │Q,K,V │ │Q,K,V │ │Q,K,V │ │
│ └──┬───┘ └──┬───┘ └──┬───┘ │
│ └─────────┴─────────┘ │
│ Склейка │
└──────────────┬──────────────────────┘
↓ Остаточная связь + Норма
↓
┌──────────────┬──────────────────────┐
│ Feed-Forward Network │
│ │
│ 512 → 2048 │
│ ↓ │
│ Активация │
│ ↓ │
│ 2048 → 512 │
└──────────────┬──────────────────────┘
↓ Остаточная связь + Норма
↓
Выходной токен (512)
Красота в простоте - всего два типа операций (внимание и нейросеть), повторенные много раз, создают невероятно мощную архитектуру.
KV-кэш: как модель генерирует текст быстро
Когда модель генерирует текст (а не просто обрабатывает готовый), возникает проблема.
Представьте: вы уже сгенерировали фразу “кот лежит на”. Теперь нужно предсказать следующее слово - “диване”.
Без оптимизации пришлось бы:
- Взять весь текст: “кот лежит на”
- Прогнать его через все 24 слоя трансформера
- Получить предсказание
- Сгенерировать “диване”
- Теперь взять “кот лежит на диване”
- Снова прогнать через все 24 слоя
- И так далее…
Очевидно это медленно - каждый раз пересчитывать всё заново.
Теперь понятно зачем KV-кэш
Идея простая: зачем пересчитывать Key и Value для старых токенов, если они не меняются?
На каждом слое модели мы сохраняем:
- Key всех уже обработанных токенов
- Value всех уже обработанных токенов
Когда приходит новый токен:
- Вычисляем только его Query, Key, Value
- Добавляем его K и V в кэш текущего слоя
- Для вычисления внимания используем:
- Q нового токена
- Все K и V из кэша (старые + новый)
- Получаем обогащенный вектор
- Идем на следующий слой
Что хранится в KV-кэше?
Для каждого слоя отдельно хранятся Key и Value всех уже обработанных токенов.
Очевидно что Query не сохраняется, потому что он всегда относится только к новому токену
Пример генерации с кэшем
-
Промпт: “кот лежит на”
- Прогоняем через модель
- На каждом слое сохраняем Key и Value этих трёх токенов
-
Генерируем “диване”:
- Пропускаем только “диване” через слои
- На каждом слое:
- Вычисляем Query, Key, Value для “диване”
- Добавляем его Key и Value в кэш
- Для внимания используем Query нового токена и все Key из кэша
- Взвешиваем все Value из кэша
-
Следующий токен: кэш уже содержит все 4 токена
Скорость увеличивается в десятки раз, потому что мы не пересчитываем старые токены.
Вектор скрытого состояния
После прохождения через все слои, у каждого токена есть вектор скрытого состояния - это его обогащенный эмбеддинг на выходе последнего слоя.
Для генерации следующего токена используется скрытое состояние последнего токена. Модель берет это состояние и предсказывает, какое слово должно быть следующим.
Почему последнего? Потому что в декодере (GPT-подобные модели) каждый токен может видеть только предыдущие токены. Значит, последний токен “видел” весь доступный контекст - он содержит максимально полную информацию!
Пример генерации в действии
Давайте посмотрим, как это работает на конкретном примере:
Промпт: “Напиши рассказ о том, как мой ученый кот говорил, что он…"
Модель обрабатывает этот текст через все слои. Механизм внимания взвешивает признаки каждого слова. Если модель обучена на русских народных сказках (например, на сборнике Афанасьева), то слово “говорил” получит высокий вес в связи с “кот” - ведь она знает про Кота-Баюна.
А вот если бы модель никогда не встречала говорящих котов, она могла бы посчитать связь “кот → говорил” маловероятной и дала бы этому слову низкий вес.
Когда модель генерирует продолжение, она использует скрытое состояние последнего токена (“он…”) и предсказывает следующее слово на основе того, что чаще всего встречалось в похожих контекстах во время обучения.
Ответ модели: “многое повидал и многое знает”
Вот так модель продолжила текст в стиле русских народных сказок - именно потому, что была обучена на них и “запомнила” характерные фразы Кота-Баюна.
Итого: как всё работает вместе
Давайте соберем всю картину воедино:
- Эмбеддинги - превращают слова в векторы координат в смысловом пространстве
- Attention (Q, K, V) - находит связи между словами, обогащает контекстом
- Multi-head - смотрит на текст с 8-12 разных точек зрения одновременно
- FFN - глубоко обрабатывает каждое слово нейросетью с нелинейностями
- Слой трансформера - это Attention + FFN с остаточными связями
- 24 слоя - постепенно создают всё более абстрактное понимание текста
- KV-кэш - ускоряет генерацию, сохраняя Key и Value от старых токенов
- Скрытое состояние - финальное представление токена, используется для предсказания
Собственно на этом пока хватит. Конечно, есть ещё куча деталей - позиционное кодирование, нормализация, техники обучения. Но основа - именно то, что мы разобрали.
Теперь, когда вас на собеседовании спросят про трансформеры - вы вполне в состоянии выкрутиться)

Теперь вы знаете, как работают трансформеры!