Agent teams: Командор и экипаж “Антилопы Гну”

В одной из прошлых статей (О Дивный Новый Мир) шла речь о том как меняется роль нашего брата, отчаянно пытающегося продержаться еще немного на плаву перед неизбежной необходимостью осваивать более полезные чем ИТ профессии - гусезаводчиков или операторов доильных аппаратов. В общем - вопрос как нам управлять агентами, которые поведенческими шаблонами вполне напоминают экипаж “Антилопы Гну”. Но Остап же справлялся, попробуем мы.
Сперва - а что это нам дает?
Сабагенты и раньше были:
- Вызывающий агент делает вызов Task tool → в его conversation history появляется tool_use блок
- Сабагент отрабатывает в своём контекстном окне (которое потом умирает)
- Результат прилетает обратно как tool_result — и ложится в conversation history вызывающего агента
В итоге - контекст вызывающего агента переполняется, и работа идет последовательно. То есть можно параллельно запускать сабагентов, но они все должны отработать и вернуть результат, чтобы вызывающий агент мог продолжить работу. Плюс - а если какой-то сабагент упал, сбоями как-то вручную нужно управлять, учитывать это в системном промпте как обрабатывать такие события без гарантий что именно так и будет - а не модель решит делать что ей больше хочется (мы не рассматриваем детерминированные процессы при помощи всяких Langchain/CrewAI)
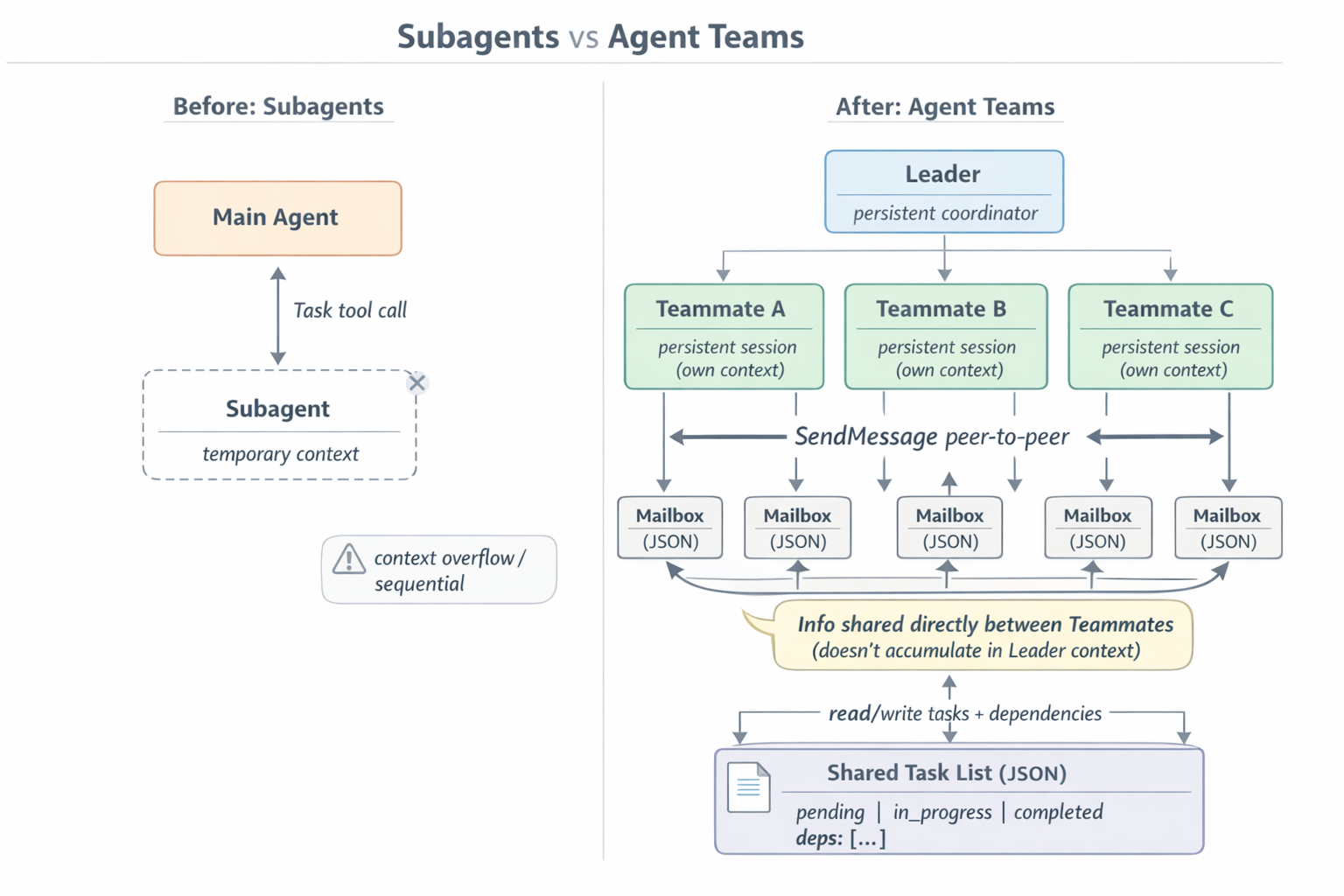
Рис. 1. Сабагенты vs Agent Teams — архитектурное сравнение
Так в чем отличие?
Из официальной документации:
Agent teams let you coordinate multiple Claude Code instances working together. One session acts as the team lead, coordinating work, assigning tasks, and synthesizing results. Teammates work independently, each in its own context window, and communicate directly with each other.
Вроде понятно:
- командир (team lead) - ваша основная сессия Claude Code,
- подчинённые (teammates, далее - агенты) - отдельные независимые сессии Claude Code, каждая в своём контекстном окне,
- общий список задач (task list) - с состояниями, зависимостями и блокировками,
- почтовый ящик (mailbox) - каналы прямого peer-to-peer обмена сообщениями между агентами.
Принципиальное отличие от сабагентов - агент не возвращает результат и не умирает. Он продолжает жить, у него есть имя, и его коллеги могут постучаться к нему с вопросом. Притом без лидера - эти агенты могут общаться друг с другом напрямую.
Включается это всё одной строчкой в ~/.claude/settings.json (фича экспериментальная и по умолчанию выключена):
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
}
}
Минимальная версия Claude Code - v2.1.32. После лидер может сказать что-нибудь вроде - “А вечером мы даём спектакль. Деньги получены. Шура! Вам придётся что-нибудь продекламировать из «Чтеца-декламатора», я буду показывать антирелигиозные карточные фокусы, а Паниковский…”.
- Research и review - несколько агентов одновременно копают разные срезы проблемы и затем оспаривают находки друг друга. Один смотрит на код через призму безопасности, второй - производительности, третий - тестового покрытия. Single-pass review такой ширины охвата не даёт никогда.
- Параллельная разработка модулей - каждый агент владеет своей подсистемой, не наступая другим на ноги. Refactor пяти модулей одновременно например.
- Дебаг через конкурирующие гипотезы - интересно. Пять агентов получают один и тот же баг и каждому даётся своя версия причины. Им предписано не только защищать свою гипотезу, но и активно оспаривать чужие. Та теория, что выживет в перекрестном огне - и есть кандидат на root cause. (Anthropic это даже в документации прямо показывает - “like a scientific debate”.)
- Cross-layer работа - один агент тащит фронт, второй бэк, третий тесты, и при этом они общаются “слушай, я поменял контракт API, тебе вот так теперь приходит”.
Чего бригадой делать не надо - последовательных задач с глубокими зависимостями, правок одного и того же файла, или мелких рутинных задач. Накладные на координацию сожрут всю выгоду. Anthropic рекомендует от трёх до пяти агентов на большинство задач - больше начинает быть контрпродуктивно из-за роста накладных на коммуникацию.
Под капотом
Но нам интересно как это работает. Вот что удалось найти:
Суть -
~/.claude/
├── teams/
│ └── {team-name}/
│ ├── config.json # конфиг команды
│ └── inboxes/
├── {agent-name}.json # почтовый ящик агента
│ └── {agent-name}.json.lock # lockfile на конкурентный доступ
└── tasks/
└── {team-name}/
└── {task-id}.json # отдельный файл на каждую задачу
config.json команды содержит массив members - имя, agent ID, тип, цвет (для отрисовки в UI), назначенную модель, prompt при запуске, режим работы. Лидер обновляет этот файл каждый раз, когда кто-то присоединяется, уходит в спячку или умирает. Документация явно предупреждает: руками не лезть, всё перетрётся.
Задачи живут отдельными JSON-файлами с состояниями pending / in_progress / completed, плюс поле dependencies со списком ID других задач. Pending-задача с неразрешёнными зависимостями не может быть взята в работу. Когда зависимость закрывается - заблокированная задача автоматически разблокируется. Никакого manual unblock не требуется.
Захват задачи (claim) - это запись поля owner в JSON, защищённая лок-файлом. Двум агентам не дадут схватить одну и ту же задачу одновременно.
А еще у Claude Code появилось пять новых инструментов:
| Tool | Назначение |
|---|---|
TeamCreate | Поднять команду: создать config.json, директорию tasks/, зарегистрировать лидера |
TeamDelete | Прибрать за собой: удалить worktrees, конфиги, task list |
TaskCreate | Создать задачу как JSON-файл (это не старый Task tool, это про todo) |
TaskUpdate | Поменять статус задачи, владельца, претензии |
SendMessage | Тот самый “почтальон”: DM, broadcast, shutdown-запросы, plan-approval |
Плюс старый Task tool получил два новых параметра - name и team_name. Если они переданы, он перестаёт быть фабрикой одноразовых сабагентов и начинает создавать полноценного агента в режиме team mode.
Агента можно запустить тремя способами — это называют бэкендом:
In-process — по умолчанию. Агент живёт внутри того же процесса Claude Code, что и лидер: свой контекст, свой message log, своя abort-controller (механизм принудительной остановки — кнопка “стоп” для конкретного агента). Переключение между агентами —
Shift+Downв терминале. Работает везде, ничего ставить не нужно.tmux pane — агент запускается как отдельный процесс
claudeв новой панели tmux. Включается черезteammateMode: "tmux"в settings или флагом--teammate-mode tmux. Не работает во встроенном терминале VS Code, Windows Terminal и Ghostty.iTerm2 — то же самое, но через
it2CLI и Python API iTerm2. Только macOS.
Код ниже это то, что Claude Code генерирует и выполняет сам, когда лидер решает поднять агента. Здесь видно, как новый процесс получает свою идентичность: имя, принадлежность к команде, ссылку на родительскую сессию. Таким образом с помощью этих флагов новый агент знает что он часть какой-то команды и кто его лидер.
| |
При tmux/iTerm2 агент — это отдельный процесс с отдельным PID, который общается с лидером исключительно через файловую систему. При in-process — они в одном процессе, но почтовый протокол тот же: JSON-файлы с лок-файлами.
А как общаются наши маленькие друзья? У каждого агента есть почтовый ящик и это физически json файл. То есть упоминал тул SendMessage - он добавляет новую запись в конец файла что-то вроде:
| |
Поля:
from- имя отправителя ("team-lead"или имя агента),text- собственно содержимое сообщения (для обычной переписки - текст; для протокольных - сериализованный JSON, об этом ниже),summary- 5-10 слов превью, нужны для отрисовки в UI,timestamp- время в ISO 8601,color- назначенный лидером цвет агента, чтобы в split-pane не путаться, кто там бормочетread- флаг “прочитано”. Все новые сообщения пишутся сread: false.
Lock-файл и атомарность записи
Вот это интересно - несколько агентов могут одновременно слать сообщение одному адресату. Если бы запись была обычной - последняя запись съела бы все предыдущие. Поэтому каждая операция записи делает следующее:
- Берёт эксклюзивную файловую блокировку на
{agent-name}.json.lock(стандартный механизм ОС — пока один пишет, другие ждут, flock). - Читает текущий JSON-массив сообщений.
- Аппендит новое сообщение.
- Пишет всё обратно.
- Отпускает flock.
Если файла inbox ещё нет - он создаётся пустым массивом []. Если lockfile взять не удалось - запись откладывается и ретраится. Reader тоже берёт flock, когда помечает сообщения как прочитанные. Это даёт сериализацию доступа без всяких сетевых очередей.
Как сообщение попадает в conversation history
Так вот у адресата сообщение должно как-то попасть в LLM-вызов_. Просто запись в файл агенту не поможет - модель этот файл сама не читает. Сообщение нужно всунуть в messages массив для следующего вызова API.
Так вот - у каждого агента есть свой execution loop - чередование “LLM-вызов → tool call → результат tool call → следующий LLM-вызов”. Это классический tool-calling loop, как в любом агенте. Перед очередной итерацией цикла runtime проверяет почтовый ящик (json файл напоминаю) агента на наличие непрочитанных сообщений.
Если непрочитанные есть - они рендерятся в XML и вставляются в conversation history. Функция-рендерер в коде Claude Code выглядит примерно так:
| |
То есть текст сообщения оборачивается в тег <teammate_message> с атрибутами teammate_id, color, summary. Этот рендер становится частью user блока, добавляется в messages для следующего вызова к модели, и сообщения помечаются как прочитанные с тем же lockfile-протоколом.
С точки зрения модели это выглядит как ещё один входящий контекст. Она его читает, осознаёт “ага, мне коллега что-то сказал”, и реагирует - либо своим ответным SendMessage, либо корректирует план работы, либо игнорирует, если контент не релевантный.
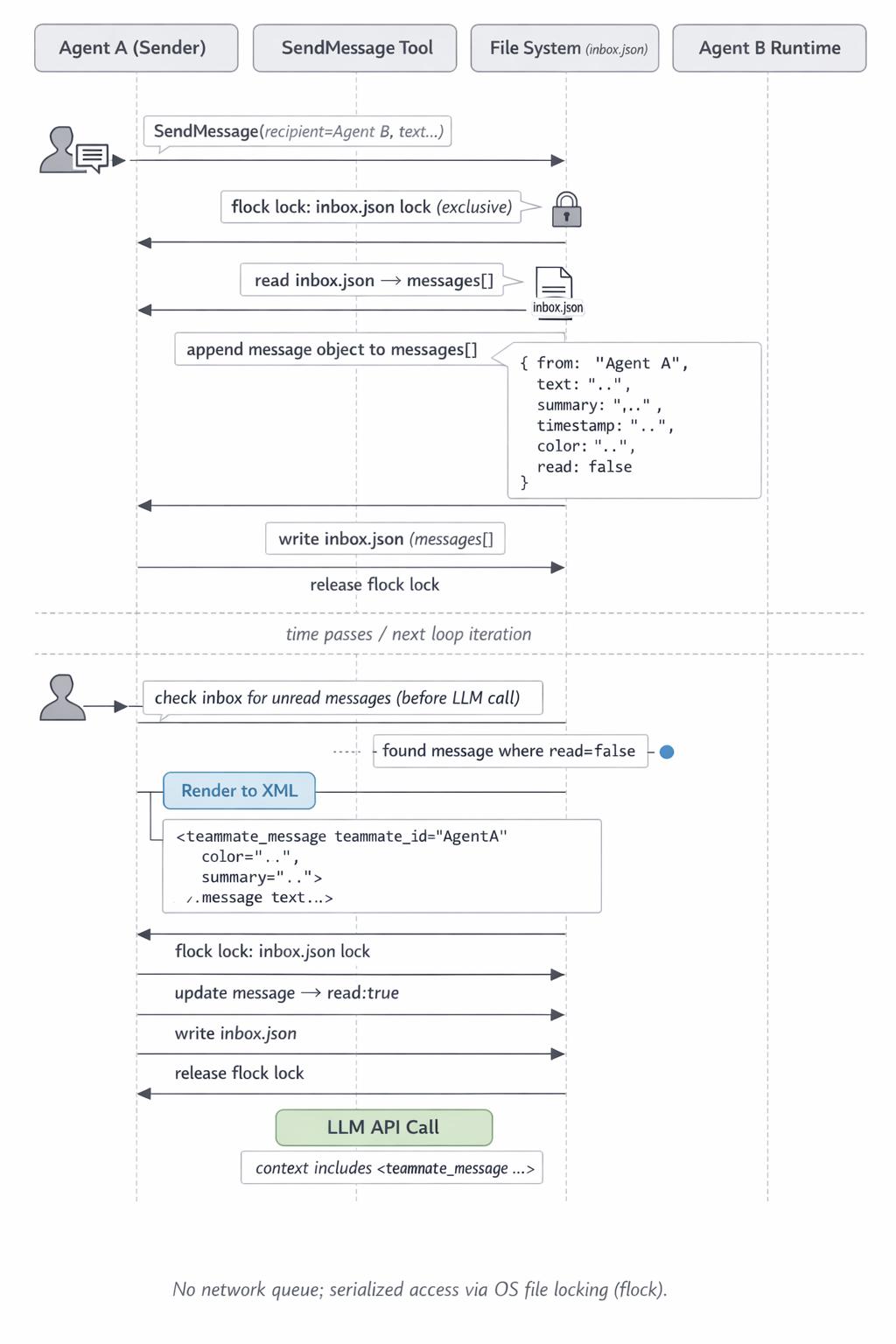
Рис. 2. Путь сообщения: от SendMessage до LLM-вызова
Пример - путь сообщения
Например у нас проблема. Пользователи жалуются: при одновременной оплате с двух устройств деньги списываются дважды. Остап поднимает команду из трёх агентов: balaganov@incident смотрит payment service, panikovsky@incident роет базу данных, kozlevich@incident проверяет retry-логику на фронте.
Шаг 1. Балаганов находит корень проблемы. Его reasoning приходит к выводу: в payment_handler.ts:112 нет транзакционной блокировки — два параллельных запроса оба читают баланс до того, как первый успел записать. Race condition. Паниковский в этот момент активно пишет миграцию, которая добавляет индекс на таблицу payments. Если он запустит её сейчас — станет ещё хуже. Балаганов решает его остановить.
Шаг 2. Балаганов вызывает tool SendMessage:
| |
Шаг 3. Tool handler обрабатывает вызов: берёт блокировку на ~/.claude/teams/incident/inboxes/panikovsky.json.lock, читает текущий массив (там одно старое сообщение от лидера с задачей), добавляет новое с полями {from: "balaganov", text: "...", summary: "...", timestamp, color: "yellow", read: false}, пишет файл обратно, отпускает блокировку. Возвращает Балаганову "Message sent to panikovsky's inbox".
Шаг 4. Балаганов получает успешный tool result и продолжает — пишет fix для payment_handler.
Шаг 5. Паниковский в это время готовится запустить db.migrate(). Runtime перед очередным LLM-вызовом проверяет его inbox. Видит непрочитанное сообщение от Балаганова. Рендерит в XML:
| |
Этот блок добавляется к messages для текущего вызова. Сообщение помечается read: true под той же блокировкой.
Шаг 6. Модель Паниковского получает контекст с этой XML-вставкой. Она “видит” предупреждение, откладывает миграцию, отвечает Балаганову через SendMessage (“понял, жду фикса — скажи когда можно”) и переключается на другую задачу из списка.
Шаг 7. Ответ Паниковского идёт тем же путём: запись в balaganov.json под блокировкой, рендер в <teammate_message> на следующей итерации цикла Балаганова, инжект в его messages.
Вот как то так - файл, блокировка, JSON, XML-тег в промпте. Минималистичный стек, который при этом не дал Паниковскому положить базу поверх живого инцидента.
Есть еще и протокольные сообщения
Помимо обычных текстовых сообщений по тому же mailbox-каналу гоняется служебный трафик. Распознаётся он просто - в поле text лежит сериализованный JSON, который пытаются распарсить через zod-схемы (TypeScript-библиотека валидации: описываешь структуру — она проверяет, совпадает ли входящий объект). Если схема подошла (ниже типы этих самых сообщений)- это управляющее сообщение, обрабатывается отдельно. Если нет - это обычный текст для модели.
Виды протокольных сообщений:
shutdown_request/shutdown_approved/shutdown_rejected- лидер просит агента закончить работу. Агент может согласиться и завершиться, или отказать с объяснением (“А я еще не доделал”). Корректно умирающий агент перед закрытием обновляет конфиг команды.idle_notification- агент сообщает лидеру, что закончил все доступные задачи и переходит в idle. Лидер видит это и может либо назначить новую задачу, либо начинать сборку финального ответа.task_completed- явное уведомление о завершении конкретной задачи (с её ID и темой). Это отдельное событие от смены поляstatusв task-файле - оно нужно для синхронизации UI и для разблокировки зависимостей.permission_request/permission_response- агент спрашивает разрешение на потенциально опасную операцию (запуск bash, запись в файл вне worktree). Лидер либо одобряет, либо отказывает с обновлёнными правами.plan_approval_request/plan_approval_response- если агент запущен сplan_mode_required: true, он сначала пишет план в read-only режиме и отправляет на одобрение. Лидер либо одобряет (с разрешением переключиться в default mode), либо отклоняет с обоснованием отказа (и агент уходит на доработку плана).
В общем эти протокольные сообщения привносят порядок в этот балаган - делая что-то вроде машины состояний.
Хуки: где можно вклиниться
Помимо самого протокола Claude Code предоставляет три специальных хука для контроля жизненного цикла команды:
TeammateIdle- стреляет, когда агент переходит в спящий режим (idle) (закончил все задачи). Если хук вернёт exit code 2 - агент не уходит спать, а получает обратно фидбек и продолжает работать. Удобно для контрольных точек вида “ты сказал что закончил, а тесты не зелёные - вот, иди работай”.TaskCreated- вызывается при создании новой задачи. Exit code 2 блокирует создание (с фидбэком). Можно валидировать формат задач, требовать упоминание acceptance criteria, etc.TaskCompleted- вызывается при попытке закрыть задачу. Exit code 2 не даёт её закрыть. Сюда можно повесить запуск тестов или линтеров перед тем, как считать задачу выполненной.
Это - те самые “явные запреты и контрольные точки”, про которые я писал в предыдущей статье (раздел «Должен» - не значит «сделает»). Только теперь они не в виде “НИКОГДА не…” в промпте, а в виде нормального exit code 2 из скрипта.
Контекст у каждого свой
Это конечно очевидное. И почтовый ящик свой. Общий зато список задач (task list), но контекстные окна агентов изолированы. И при создании агент конечно не наследует контекст лидера.
Что агент получает при рождении:
- свой собственный системный промпт (включая
CLAUDE.mdиз рабочей директории), - подключённые MCP-сервера,
- доступные skills,
- spawn prompt от лидера (задача, контекст, инструкции).
А значит агенты не могут опереться на работу друг друга. Если security обнаружил критичную проблему - coder про неё узнает, только если security явно ему напишет через SendMessage. Сам факт того, что коллега что-то нашёл, никому кроме него не известен. Поэтому хорошие промпты для команды содержат фразы вроде “обменивайтесь находками через сообщения, оспаривайте подходы друг друга”.
Например:
Users report the app exits after one message instead of staying connected.
Spawn 5 agent teammates to investigate different hypotheses. Have them talk to
each other to try to disprove each other's theories, like a scientific
debate. Update the findings doc with whatever consensus emerges.
Из минусов кстати у нас расход токенов. Полный контекст агента считается отдельно от лидера. Команда из лидера и трёх агентов с 10K инициализации каждый - это 40K токенов на старте вместо 10K, как было бы в одиночной сессии.
Как это отлаживать
Ну и как всегда - агенты тупят, шлют друг другу не то, выпадают в idle с незакрытыми задачами и так далее. Это всё пока экспериментально, и про это Anthropic честно пишет.
Способы посмотреть, что происходит:
- В split-pane режиме каждый агент в своей панели tmux. То есть можно наблюдать живой поток сознания. Можно даже взять управление и сказать агенту напрямую “перестань кидаться по файлам, посмотри сначала вот эту конкретную функцию”.
- В in-process режиме Shift+Down циклически переключает фокус между агентами. Enter - провалиться в сессию конкретного агента. Escape - прервать его текущий ход.
- Ctrl+T переключает task list - видно, кто что делает, что в отложено, что заблокировано.
- Файлы на диске - ну и так можно
cat ~/.claude/teams/{team}/inboxes/{name}.json | jqвидеть переписку. И~/.claude/tasks/{team}/- реальный статус задач. Если что-то висит - часто это видно прямо в файле.
Типичные грабли и как их обходить:
- Лидер сам начинает реализовывать, не дождавшись агентов - встречается часто. Ну тут лечим промптом что-то типа: “Wait for your teammates to complete their tasks before proceeding”.
- Агент ушёл в сон (idle), не отметив задачу завершённой - её зависимости остаются заблокированы. Опасайтесь молчаливых задач. Лечится либо ручным
taskUpdate, либо командой лидеру “проверь незакрытые задачи и закрой реально выполненные”. - Лидер решил, что команда закончила, когда работа на самом деле не сделана_ - сказать “продолжай, солнце еще не зашло”.
/resumeпосле рестарта не восстанавливает in-process агентов. Лидер может пытаться писать “мёртвым” агентам. Лечится фразой “создай новых агентов, старые на том свете”.- Permission prompts задалбывают - все запросы прав от агентов всплывают к лидеру, и если у вас не настроены
permissionsв settings, получится бесконечный поток вопросов. Решение - заранее разрешить рутинные операции в permission settings. - может что-то еще
И главное — не оставляйте бригаду без присмотра надолго. Лидер — ваша основная сессия, с ним вы общаетесь как обычно: просто напишите «что у нас по статусу» прямо в терминале. Лучше так иногда заглянуть, чем потом обнаружить, что три агента с обеда дискутируют о чём-то своём.
А чего нет?
Ну я пока обнаружил следующее:
- Один лидер - одна команда за раз. Не закончил работу с текущей - не создашь новую.
- Агенты не могут создавать своих агентов. Иерархия плоская: лидер - агент. А хотелось бы рекурсию.
- Передать лидерство нельзя.
Чем это отличается от Copilot Custom Agents
Копилот агенты - прямой аналог старых Task tool сабагентов из Claude Code. Главный агент через tool agent/runSubagent создает дочерний агент с собственным контекстным окном. Тот что-то делает - и возвращает результат.
С 1.107 (December 2025) сабагенты можно запускать параллельно. С 1.116 в Agent Sessions view они стали виднее, и можно раскрыть конкретного сабагента и посмотреть его полный prompt и результат.
Но они не общаются друг с другом. Они не общаются вообще. Координирует родительский агент, синтезируя результаты после того, как все вернулись. То, что Claude Code умел с самого начала.
Agent Sessions view (мульти-агентский dashboard)
Это куда Microsoft пошёл стратегически - в одном окне VS Code собрать все типы агентов: Local Agent (Copilot, обычная сессия), Background Agent (фоновая задача), Cloud Agent (выполняется на серверах GitHub, для чего-то продолжительного), Codex Agent (даже не пробовал). Видно, что где запущено, можно переключаться, можно делегировать. Но опять - это не про межагентскую координацию - это про организацию работы человека с несколькими агентами.
Agent Debug Logs (отладка предыдущих сессий)
И вот тот самый отсюда 1.116.Под флагом github.copilot.chat.agentDebugLog.fileLogging.enabled Copilot пишет на диск хронологический лог всех событий сессии: запросы, ответы модели, вызовы тулов, результаты. Раньше можно было смотреть только текущую сессию - теперь сохраняется локально, и можно открыть старые.
Где они расходятся принципиально
Если коротко:
| Аспект | Claude Code Agent Teams | Copilot Agents |
|---|---|---|
| Архитектура | Лидер + агенты с общим списком задач и почтовыми ящиками | Координатор/сабагент или цепочка передач (один агент завершил → передал следующему) |
| Межагентская коммуникация | Напрямую между агентами через JSON-ящики + XML-вставка в историю диалога | Только через возврат результата родителю |
| Параллелизм | Несколько агентов работают одновременно и обмениваются | Параллельные сабагенты без обмена; либо цепочка передач по очереди |
| Координация | Децентрализованная: агенты сами захватывают задачи, ставят зависимости | Централизованная: родительский агент распределяет и синтезирует |
| Видимость | tmux-панели + Shift+Down навигация | Agent Sessions view с раскрываемыми блоками сабагентов |
| Отладка прошлых сессий | Через файлы в ~/.claude/teams/ и ~/.claude/tasks/ | Agent Debug Logs (1.116+) |
| Лидер живёт | Постоянно, до удаления команды | Создаётся и умирает у сабагентов; живёт постоянно у родительского |
| Можно ли создавать агенту других | Нет, плоская иерархия | Тоже нет (сабагенты не могут создавать своих сабагентов) |
Если поверх этой таблицы попытаться найти философию, то выходит так. Anthropic ставит на распределённую координацию: лидер задаёт направление, а дальше агенты могут самоорганизовываться, обмениваться, оспаривать друг друга, без обязательного контроля через лидера. Microsoft ставит на контролируемый workflow: каждый шаг через человека или родительского агента, граф состояний с явными контрольными точками.
В общем выбирайте сами.
Источники и дополнительные материалы
- Orchestrate teams of Claude Code sessions - официальная документация
- Introducing Claude Opus 4.6 - анонс
- I reverse engineered how Agent Teams works under the hood - vicdotso про внутренности
- Полный gist с фактическим кодом протокола - реверс-инжиниринг инструментов и mailbox
- Addy Osmani: Claude Code agent teams - заметки про peer-to-peer и контекстную изоляцию
- VS Code 1.116 release notes - Agent Debug Logs
- Subagents in Visual Studio Code - Copilot сабагенты
- Custom agents in VS Code - .agent.md и handoffs
- Your Home for Multi-Agent Development - стратегия VS Code про мульти-агентов