“Study, Study, and Study Again!” (c) V.I. Lenin
Why bother?
So here’s the task: build an AI assistant that uses an SLM (Small Language Model) to extract personalized information about the user. Why SLM? Well, privacy — data doesn’t leave the device, plus cost savings. We don’t need the details here — the point is to figure out whether this is even feasible with acceptable quality, what thorns await us, and what to do about it.
Let’s go!
SLM
Let’s see what’s available on Hugging Face — we’ll go with the fresh Qwen3.5-0.8B — seems close to what we need, 0.8B parameters, should do. Now our task is to figure out how smart the model is for our purposes — and that’s not straightforward. Ideally we want something like Google Memory Bank. By the way, Google published their vision on this: Context Engineering: Sessions and Memory — it’s very interesting, especially the section on Memory Generation: Extraction and Consolidation. Here are the key takeaways:
- Memory Generation is an ETL pipeline, not just “save what the user said.” Google splits the process into Extraction (pulling facts from the conversation) and Consolidation (merging, updating, and deleting facts in the store). Without the second stage, memory quickly fills up with duplicates and contradictions.
- Extraction works best with a schema. Instead of a vague “remember everything important,” you give the model specific categories/fields to extract (preferences, biographical facts, etc.). This dramatically improves accuracy and predictability.
- Consolidation — three operations: Merge, Delete, Create. A new fact can update an existing one, delete an outdated one, or create a new entry. Without this logic, the model will simultaneously remember that the user “loves wine” and “quit drinking.”
- Memory Provenance determines priority. Google introduces a hierarchy: explicit user instructions > facts from dialogue > model inferences. In case of conflict, the higher-priority source wins.
- When to generate — a separate question. You can do it after each message, at the end of a session, or on a schedule. Each approach has its own trade-offs in latency, cost, and completeness. Google recommends end-of-session as a reasonable balance.
- Memory generation quality is the main problem. Literally: “The quality of the generation stage is arguably the most critical component of the entire memory system.”
But expecting all of this from our little SLM is unrealistic — our task is to figure out what we can squeeze out of it at maximum.
Let’s start with tests. We take the base Qwen 3.5 0.8B model as-is and feed it a bunch of test messages. Something like “I live in Minsk and work as a welder” — and the model should return a JSON with facts: location — Minsk, profession — welder.
We have three key metrics:
- Precision — of everything the model extracted, how much is actually correct? If the model found 10 facts and 5 are correct — precision = 50%. Roughly speaking, it’s about “is the model making things up?”
- Recall — of all the facts that WERE in the text, how many did the model find? If there were 10 facts and the model found 5 — recall = 50%. It’s about “is the model missing important stuff?”
- F1 — the harmonic mean of precision and recall. One number that says “overall good or not.” F1 = 1.0 — perfect, F1 = 0 — total failure.
And here are the base model results: F1 = 0.49. Precision 0.46, Recall 0.53. So out of the box, the model catches roughly half the facts, and half of what it “finds” is garbage. Not great. On the other hand, the model at least understands the task and outputs valid JSON 100% of the time. So there’s potential.
But I ran into a major problem with model hallucinations. That’s when the model invents facts that don’t exist. You ask “what’s the weather today?” — and it tells you: “user is interested in meteorology.” You ask “translate this to French” — you get: “user knows French.” There were no personal facts in the message — the model just made them up. In my tests, the base model hallucinated false facts in ~92% of test cases. And out of empty cases (where the correct answer is an empty list), the model correctly returned nothing only in 78% of cases — in the remaining 22% it invented facts from thin air. That’s obviously unacceptable.
So I’ll try to fine-tune the model to do what I need.
A bit of theory
Let’s dig into the details — how exactly we fine-tune the model. As you all know, training essentially comes down to updating the model’s tensor weights. But there are a lot of those weights — and that’s where LoRA (Low-Rank Adaptation) comes in.
Let’s be concrete. In each transformer layer, there’s a weight matrix W of size, say, 4096 × 4096 — that’s 16 million numbers. With regular fine-tuning, we update all of them. It’s expensive, tedious, and for each task you need a full copy of the model.
The LoRA idea: when we fine-tune, the weight changes ΔW in practice only affect a small part of the entire space. A rough analogy: imagine a huge 4096 by 4096 table — but the number of actually meaningful “directions” in it is just 16. Why store and update all 16 million cells then?
Instead, LoRA decomposes the ΔW correction into a product of two small matrices:
ΔW = B × A
- A — a compression matrix: takes the 4096-dimensional input and projects it into a narrow space of dimension r (in our case r = 16)
- B — an expansion matrix: projects back from 16 to 4096
During inference, input vector x goes along two paths — through the original frozen weights W and in parallel through our pair A and B. The results are summed:
h = W · x + B · A · x
The original weights W are left untouched — we only train the small A and B.
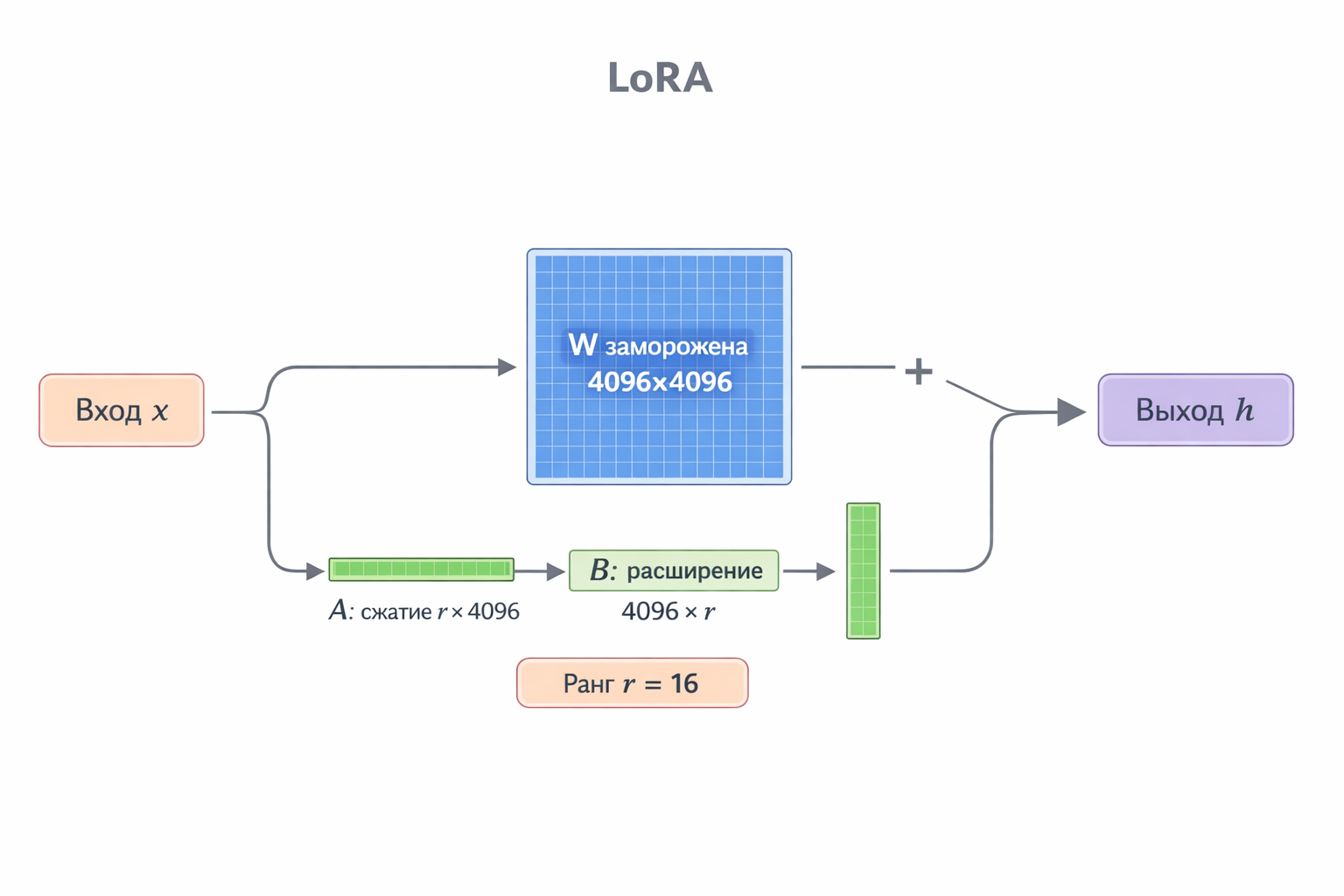
So instead of 4096 × 4096 = 16,777,216 trainable numbers per layer, we have (4096 × 16) + (16 × 4096) = 131,072 — 128 times fewer.
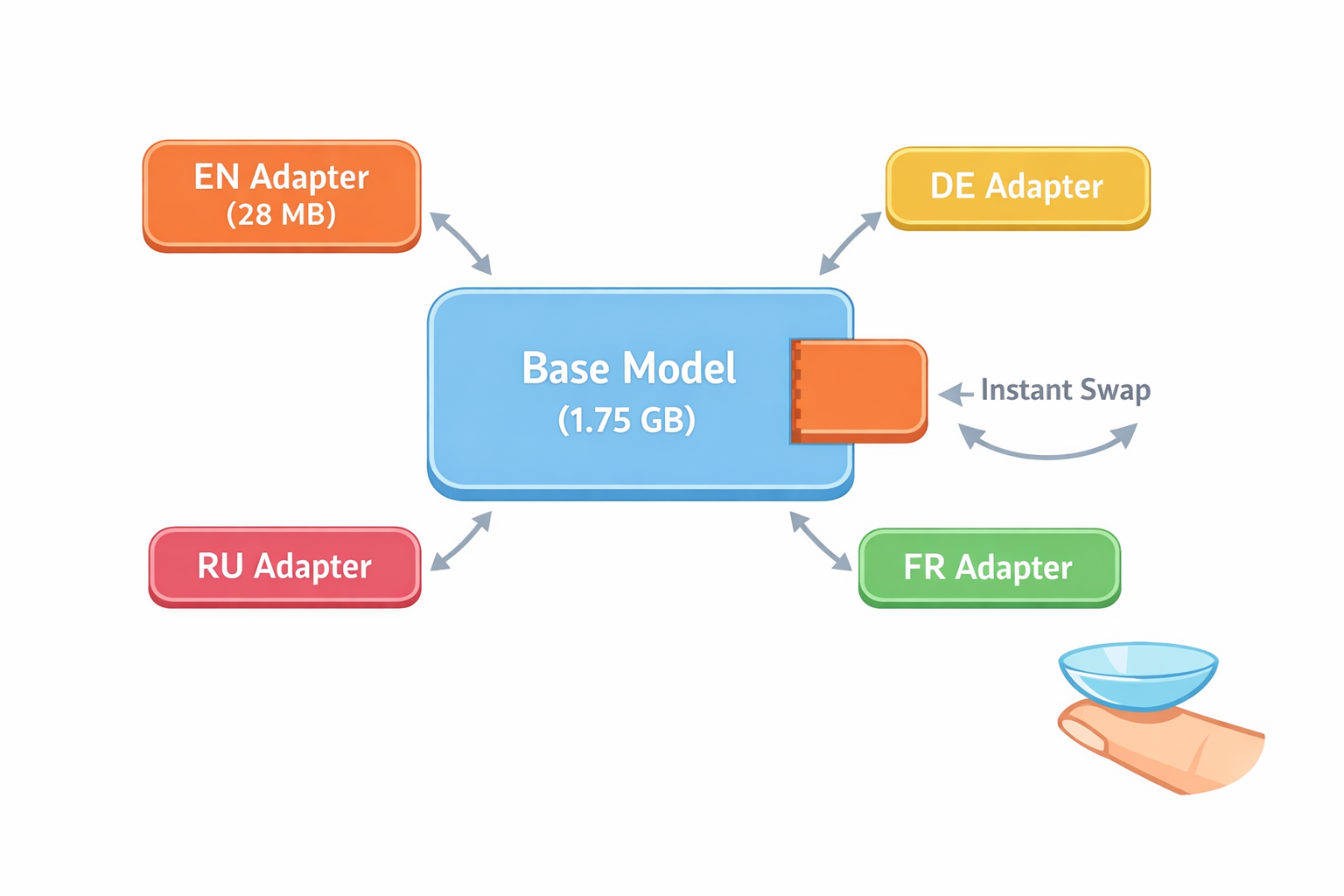
In practice: the base model weighs ~1.75 GB, while the LoRA adapter is just ~28 MB (~1.5% of the model). And importantly — you can make separate fine-tuned adapters for different tasks without touching or copying the base model. Moreover, LoRA adapters are a universal format: they work with MLX (Apple Silicon), GGUF (llama.cpp / Ollama), and plain PyTorch. An adapter is just a set of matrices A and B that are applied to the base model at load time.
Training data
The model needs examples — “here’s a user message, here’s what facts to extract from it.” The more diverse the examples, the better the model generalizes. We’re obviously not writing them by hand, so we ask an LLM to generate them.
Simple idea: we describe fact categories (location, diet, interests, expertise, goals, etc.), give the format — and ask the LLM to generate diverse message examples with correct answers. We also need “empty” examples — ones containing no facts — to get rid of the hallucinations described above.
The training data format is standard chat-format for MLX LoRA. Each example is a dialogue of three messages:
| |
The system prompt is the same for all examples — it describes categories and extraction rules. The user message is the input. The assistant’s response is the gold-standard JSON with facts. The model learns to reproduce exactly such responses.
And how to evaluate quality? We care about semantic match, not exact wording. Here we also use an LLM — the LLM-as-judge approach. We take our test datasets (non-overlapping with training data), run them through our model, and then use a powerful LLM to compare the extracted facts against the reference — i.e., semantic matching.
First iteration
So, we have the dataset — let’s start training. But first, let’s sort out the terminology:
Iteration (training step) — one training step: the model takes one example from the dataset, computes the error, and updates the weights. With batch_size=1, one iteration = one example.
Epoch — one complete pass through the entire dataset. If the train split has ~1000 examples and batch_size=1, then one epoch = ~1000 iterations.
How long to train — a balancing act. Too little — the model won’t learn anything. Too much — it overfits, meaning it memorizes the training examples and can’t work with new data. Ideally, we want the model to generalize.
First attempt: ran for 200 iterations (~28% of one epoch) — F1 = 0.52. Slightly better, but within the margin of error. Hallucinations on empty cases improved though — EmptyAcc went from 78% to 86%. So the model started inventing facts from thin air a bit less often, but overall the improvement was marginal.
It became clear that both the training data and the training configuration needed serious work. I tweaked the learning rate, increased the number of examples, and raised iterations to 500. Subsequent attempts yielded:
| Attempt | Iterations | F1 | Precision | Recall | EmptyAcc |
|---|---|---|---|---|---|
| Base | — | 0.49 | 0.46 | 0.53 | 78% |
| #1 | 200 | 0.52 | 0.49 | 0.55 | 86% |
| #2 | 500 | 0.78 | 0.76 | 0.80 | 86% |
| #3 | 500 | 0.80 | 0.77 | 0.84 | 86% |
| #4 | 500 | 0.80 | 0.83 | 0.78 | 100% |
The key breakthrough — attempt #4: EmptyAcc = 100%, meaning the model completely stopped hallucinating on empty cases. If there are no personal facts — it honestly returns an empty list. And F1 went from 0.49 to 0.80 — that’s a serious result for a 0.8B parameter model.
But a limitation of the small model also emerged. The model is multilingual — but when I tried to teach it to work with user memory in multiple languages, quality dropped across the board. The model just doesn’t have enough capacity to extract facts equally well in different languages. I believe this is due to the model size. Conclusion — we can fine-tune for one thing at a time.
OK — so we train the model to extract facts in English only. User messages in other languages get pre-translated to English before being fed to the SLM. That’s how we store them too.
Or alternatively — you can fine-tune for a specific language and get a separate LoRA adapter, which by the way can be swapped on the fly. Kind of like plugins.
I tried fine-tuning for Spanish — and immediately got F1 = 0.90 on Spanish tests. But for my use case I don’t see much point in this approach — so it’s more of a reference.
Conclusions
So, what did we find out. An SLM with 0.8B parameters can be taught to extract personal facts from messages — and do it reasonably well. F1 from 0.49 to 0.80, hallucinations from 22% down to zero. For a model that weighs less than two gigabytes — that’s a solid result. On top of that, it can be quantized — made even smaller (we’re using the bf16 version). But we still need to test how much quality drops at Q8, for example.
So:
- Data is everything. Not architecture, not hyperparameters — it’s the quality and diversity of training examples that matter. The first iterations with bad data gave near-zero improvement. As soon as we added more “tricky” empty examples (sarcasm, negations, mentions of other people’s facts, subjunctive mood), diversified implicit cases, and tuned the learning rate with cosine decay — metrics jumped from 0.52 to 0.78 in a single attempt.
- Small model — one task. Multilingual support is not for 0.8B. The model simply doesn’t have enough capacity to work equally well across multiple languages. Solution — one language for extraction, translate at the input.
- LoRA is powerful. A 28 MB adapter instead of a full model copy at 1.75 GB. You can keep separate adapters for different tasks and languages, swapping them on the fly.
- LLM-as-judge. Semantic evaluation via a large LLM is probably the only way to measure fact extraction quality.
- Empty examples. Without them, the model hallucinates in 22% of cases. With them — 0%. The model must be able to say “nothing here” just as confidently as it extracts facts.