Embeddings, Attention, FNN and Everything You Wanted to Know But Were Afraid to Ask
Introduction
With this, I’m trying to start a series of articles dedicated to LLMs (large language models), neural networks, and everything related to the AI abbreviation. The goals of writing these articles are, of course, self-serving, because I myself started diving into these topics relatively recently and faced the fact that there seems to be a mass of information, articles, and documents written in small print with pretentious diagrams and formulas, reading which, by the end of a paragraph, you forget what the previous one was about. Therefore, here I will try to describe the essence of the subject area at a conceptual level - and so I promise to avoid mathematical formulas and tricky graphs as much as possible, seeing which, the reader inevitably catches themselves wanting to close the browser tab and visit the nearest liquor store. So - no formulas (except the simplest ones), no pretentiousness, no pretensions of looking smarter than I am. Your grandmother should understand these articles, and if that didn’t work out - then I failed the task.
So, embeddings
This is a very good word - to look solid, don’t forget to insert this word in any context when the conversation goes into the area of discussing AI. The chances that someone will ask you to clarify what it is and start asking follow-up questions are minimal, but at least your authority in the eyes of others won’t drop, and who would want to reveal their ignorance with questions? Nevertheless, considering that you’ll likely have to go to job interviews again soon - let’s try to figure out the essence of the phenomenon at a high abstract level.
Let’s take the word “cat”. Let’s take an abstract but trained LLM model. Somewhere in the depths of its matrices-dictionaries it contains this word. It looks approximately like this:
| Word | Vector |
|---|---|
| Cat | [0.2, -1.3, 3.4, 5.6…] |
So - what do these vectors mean? These numbers? And these numbers are the coordinates of a cat in semantic dimensions.
But how - how can a soulless machine have the concept of semantic dimension? Right - it can’t. But they exist. Where did they come from? As a result of training the model on information generated by humanity and which the model was able to reach during the training phase. (For those who need details - Hugging Face Space). But we’ll talk about the details of training in the next articles.
Let’s suppose that some extraterrestrial being asks you to explain - what is a cat? How will you do this? Obviously - you’ll try to go through the features:
- Cat? Well, it’s rather small (relative to what? A virus? A bacterium? A blue whale? We need a measurement scale - let it be from 0 to 10)
- It’s fluffy (How much? Again we need a scale. What about a Sphynx?)
- In short, it also meows (Frequency characteristics? Spectrum shape?)
- It’s quite intelligent (Again - an intelligence scale, as we understand it?)
During the training phase, the model analyzed words that frequently appeared near the word “cat”, and based on this data calculated its characteristics. For example, near the word “cat” frequently appeared descriptions like “fluffy”, “small”, “catches mice” and others. This is exactly how the coordinates of a word in the multidimensional feature space are formed.
In other words, the model doesn’t operate with features (semantic characteristics) in the human sense, but only identifies statistical patterns in the text. Thus, dimensions related to size, behavioral characteristics, or degree of intelligence may emerge, even if the latter is not literal.
If we simplify the multidimensional space to two dimensions, we can imagine where the coordinates of “cat” would be relative to other entities:
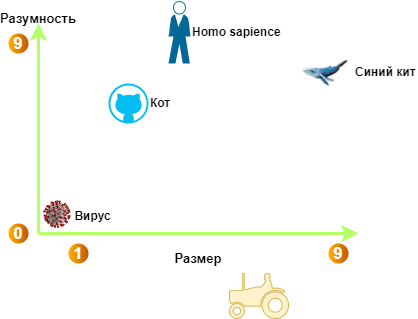
Semantic coordinates of words in the space of sentience and size
So - a cat is quite intelligent and small in size. For comparison, other representatives of our fauna and even a tractor are indicated - as a certain opposite of the semantic meaning of a cat: large and non-intelligent. Of course, this is a crazy simplification, because in modern models there are up to 2024 or more such semantic dimensions. That is, these could be other dimensions such as:
- Physical characteristics
- Size
- Weight
- Shape
- Color
- Behavioral characteristics
- Intelligence
- Activity
- Danger
- Sociality
- Functional and role features
- Usefulness
- Domestication
- Emotional coloring
- Temporal belonging
- …
To simplify this representation, you can imagine a three-dimensional space where each galaxy is a semantic space. In this space, each star represents a word, and its coordinates determine its semantic position. For example, somewhere in this space there will be a star named “cat”. Nearby, there may be stars with names like “dog”, “hamster”, and “mouse”, since these words are semantically close to each other. But “shark” will be further away - it seems to also be the animal kingdom, but in the class of cartilaginous fish.
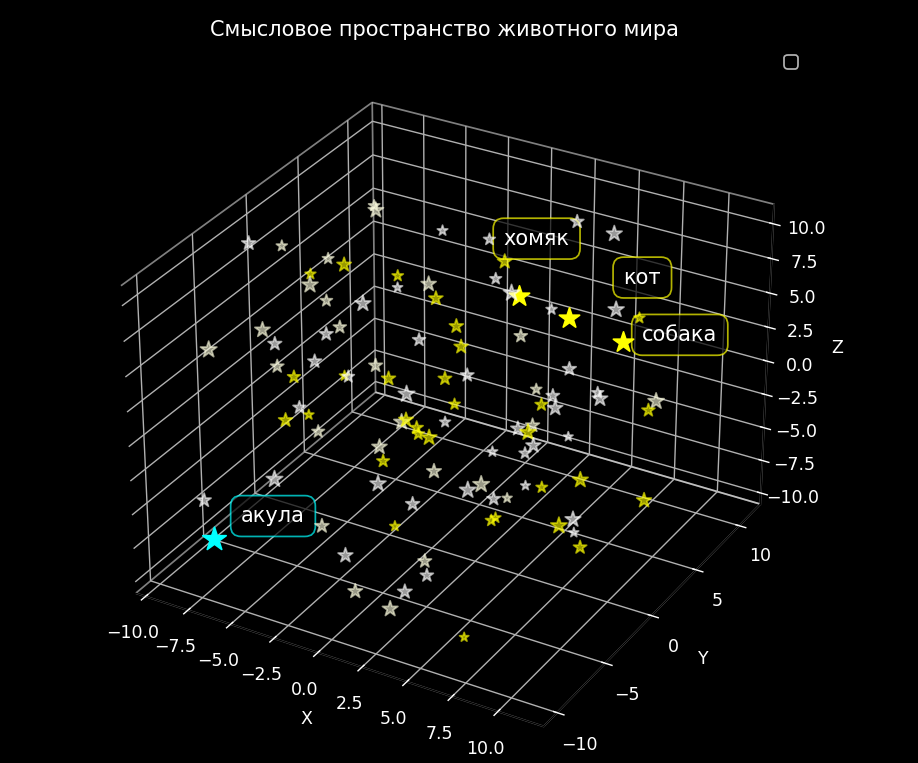
Coordinates in semantic space
And now let’s remember the Multiverse theory (yes, Everett’s interpretation, string theory) and imagine that there are many more spatial dimensions than three - and each dimension defines its own semantic space.
Well, now that we’ve figured out embeddings, let’s move on to the “attention” mechanism.
Attention, Attention! Or how the model understands context
So - we’ve figured out that we have some multidimensional semantic space, but at the level of individual words. But what if we’re talking about homonyms?
Imagine: a person of male gender tells you “I have a new braid”.
What is a “braid”? A tool for mowing grass or has he embraced European “values”?
To understand, you need to consider the context - for example, what was said earlier - “I’m at the dacha” - which means, most likely, we’re talking about an agricultural tool. Or “I came out of the barber” - then things are sad.
But how does the model understand a sentence and its meaning? Especially if we’re talking about a generative model - something like:
Prompt: “Write a story about how my learned cat said that he…"
How does the model understand what I want from it? How does it understand the context of the entire text? This is what the “attention” mechanism was invented for.
The problem that attention solves
We need to understand the relationship of words in the text. For example - that “learned” is a characteristic of the cat, or “he” - again refers to the cat. Of course, we can’t determine all such connections with 100% certainty, but at least with high probability.
Analogy with a detective: how weights work
Imagine that I’m a detective investigating the poisoning of a rich person. Naturally, I determine the circle of suspects - who was nearby at the time of the crime, who had access to the victim, and so on.
Next - I try to understand the motives: someone craved inheritance (greed), someone felt personal dislike, someone was afraid of disclosure of some secrets. Analyzing the potential motive of each suspect, I sort of assign a “weight” to the set of motives. For some it’s greater, for others less, and to some the deceased was completely indifferent.
Thus I narrow down the circle of suspects, and exclude some altogether. The attention mechanism does approximately the same thing - assigns a “weight” to each word relative to all other words in the text.
Three magic matrices: Query, Key, Value
Imagine you’re in a library. You have:
- A search query (Query) - “show me everything about cats”
- A catalog (Key) - cards of all books with brief descriptions
- The books themselves (Value) - the content you want to get
The attention mechanism works in a similar way. Only instead of a library we have text, and instead of books - words.
Step 1: Forming Query (Request)
We take the word “cat” from our text. It already has an embedding - a vector of coordinates in semantic space. But we need to turn it into a query: “What words in the text will help me better understand this cat?”
To do this, we run the cat’s embedding through a special trainable Query matrix. We get a new vector - this is our “search query”. This matrix is trained to highlight exactly those features that are important for finding connections.
Step 2: Forming Keys for all words
Now we take ALL words from the text: “my”, “learned”, “cat”, “said”, “that”, “he”…
For EACH word we create its “key” - a description by which it can be found. We run the embedding of each word through the Key matrix. We get keys for all words.
Step 3: Comparing Query with Keys - looking for similar ones
Now the magic - we compare our query about the cat with the key of each word. The model calculates how similar they are.
The higher the score - the stronger the connection. For example:
- “learned” gets a high score - this is a characteristic of the cat
- “said” gets an average score - an action of the cat
- “my” gets a low score - just indicates the owner
Then the model normalizes these scores - turns them into weights from zero to one, which sum to one. For example:
- weight “learned” = 45%
- weight “said” = 35%
- weight “my” = 15%
- weight of the rest = 5%
Step 4: Getting Value (Content) and weighing
Now for each word we take its “content” - run it through the third Value matrix. It extracts from each word the information that needs to be passed further.
And we create an enriched embedding for the word “cat”, mixing the content of all words considering the weights:
- take 45% from “learned”
- add 35% from “said”
- add 15% from “my”
- add 5% from the rest of the words
So - now the embedding of the word “cat” contains information about the context: that it’s learned and that it said something.

Attention mechanism in action
Why three different matrices?
It would seem - why such complications? Why not one matrix?
- Query - highlights “what we’re looking for” (what features are important for connections)
- Key - highlights “what we can be useful with” (what information we carry)
- Value - contains “what we give” (actual data)
These are like three different views on the same word. And all three matrices are trained - the model itself finds optimal values.
Multi-head attention: when one opinion isn’t enough
Imagine a veterinary clinic where a cat was brought. A team of specialists examines it: one checks the general condition, another listens to the heart, a third looks at the teeth, a fourth checks reflexes. Each veterinarian sees their part of the picture.
One attention mechanism is like one veterinarian who looks only from one point of view. He might notice temperature, but miss something important about teeth or paws.
Many heads = many points of view
What if we have many specialists, each looking at our cat in their own way?
- Head 1: looks for the connection “who → does what” → sees “cat → said”
- Head 2: looks for the connection “where → happens” → might notice prepositions
- Head 3: looks for semantic closeness → “learned” ↔ “said” (intelligence + speech)
- Head 4: tracks coreference → understands that “he” = “cat”
And so on - usually models have 8-12 attention heads.
How does this work technically?
Very simple - instead of one set of Query, Key, Value matrices, we have 8 sets:
Head 1: W_Q¹, W_K¹, W_V¹
Head 2: W_Q², W_K², W_V²
...
Head 8: W_Q⁸, W_K⁸, W_V⁸
Each head:
- Independently calculates its Query, Key, Value
- Calculates its attention
- Gets its enriched vector
Then all outputs are concatenated into one long vector and run through a final matrix.
Important nuance: dimensionality doesn’t change!
If the original embedding was size 512, then the output will also be 512.
How? Simply, each head works in its own subspace:
- Total size: 512
- Heads: 8
- Size of each head: 512 divided by 8 = 64
That is, each head looks at the text through its own 64 dimensions out of all 512. Then the results are concatenated back: eight pieces of 64 give 512 again.
It’s as if you divided your brain into 8 specialized mini-brains, each expert in their field, and then combined their conclusions.
What does a transformer layer consist of?
Now that we’ve figured out attention, let’s look at the full picture - what is one transformer layer?
A transformer layer consists of two main parts:
Part 1: Multi-head attention mechanism
This is everything we just discussed:
- Take embeddings of all tokens
- For each head (for example, 8 heads) calculate Q, K, V
- Calculate attention
- Concatenate results
- Apply final matrix
Important: this is not a neural network, but just linear transformations plus a weighted sum. There’s no nonlinear activation here.
Part 2: Feed-Forward Network (FFN) - and here’s the neural network
After attention has processed the text and identified connections between words, this information needs to be additionally digested. This is where the real neural network appears.
FFN is a two-layer fully connected neural network. It works like this:
- First expands the vector (for example, from 512 to 2048)
- Applies a nonlinear activation function (this is where the “brain” is)
- Then narrows back (from 2048 to 512)
This is applied to each token separately - independently of others.
Why is FFN needed if there’s attention?
Great question! Here’s why:
- Attention answers the question: “Who to communicate with?” - finds connections between words
- FFN answers the question: “What to think?” - deeply processes each word separately
Without FFN, the model would be purely linear (only multiplications by matrices), and therefore - weak. It’s the ReLU in FFN that gives the transformer expressive power and the ability to model complex nonlinear dependencies.
Full path of a token through one layer
So, what happens to one token when it passes through a transformer layer:
Input vector of size 512
Multi-head attention mechanism:
- Calculate Query, Key, Value for all heads
- Calculate weighted sum
- Get processed vector
Residual connection and normalization:
- Add original vector to processed one
- This helps not lose information
FFN neural network:
- Expand vector, apply activation, narrow back
Again residual connection and normalization
Output vector goes to the next layer
And so 12-24 times (that’s how many layers are usually in modern models).
Visualization of a transformer layer
Input token (512)
↓
┌─────────────────────────────────────┐
│ Multi-Head Attention │
│ │
│ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │Head 1│ │Head 2│ │Head 8│ │
│ │Q,K,V │ │Q,K,V │ │Q,K,V │ │
│ └──┬───┘ └──┬───┘ └──┬───┘ │
│ └─────────┴─────────┘ │
│ Concatenation │
└──────────────┬──────────────────────┘
↓ Residual connection + Norm
↓
┌──────────────┬──────────────────────┐
│ Feed-Forward Network │
│ │
│ 512 → 2048 │
│ ↓ │
│ Activation │
│ ↓ │
│ 2048 → 512 │
└──────────────┬──────────────────────┘
↓ Residual connection + Norm
↓
Output token (512)
Beauty in simplicity - just two types of operations (attention and neural network), repeated many times, create an incredibly powerful architecture.
KV-cache: how the model generates text fast
When the model generates text (and doesn’t just process ready-made text), a problem arises.
Imagine: you’ve already generated the phrase “the cat lies on”. Now you need to predict the next word - “the sofa”.
Without optimization, you’d have to:
- Take all the text: “the cat lies on”
- Run it through all 24 transformer layers
- Get a prediction
- Generate “the sofa”
- Now take “the cat lies on the sofa”
- Run it through all 24 layers again
- And so on…
Obviously this is slow - recalculating everything anew each time.
Now it’s clear why we need KV-cache
The idea is simple: why recalculate Key and Value for old tokens if they don’t change?
On each layer of the model we save:
- Keys of all already processed tokens
- Values of all already processed tokens
When a new token arrives:
- Calculate only its Query, Key, Value
- Add its K and V to the cache of the current layer
- To calculate attention we use:
- Q of the new token
- All K and V from the cache (old + new)
- Get enriched vector
- Go to the next layer
What is stored in KV-cache?
For each layer separately, Keys and Values of all already processed tokens are stored.
Obviously Query is not saved, because it always relates only to the new token
Example of generation with cache
Prompt: “the cat lies on”
- Run through the model
- On each layer save Key and Value of these three tokens
Generate “the sofa”:
- Pass only “the sofa” through the layers
- On each layer:
- Calculate Query, Key, Value for “the sofa”
- Add its Key and Value to the cache
- For attention use Query of the new token and all Keys from the cache
- Weight all Values from the cache
Next token: cache already contains all 4 tokens
Speed increases by tens of times because we don’t recalculate old tokens.
Hidden state vector
After passing through all layers, each token has a hidden state vector - this is its enriched embedding at the output of the last layer.
To generate the next token, the hidden state of the last token is used. The model takes this state and predicts which word should be next.
Why the last one? Because in the decoder (GPT-like models) each token can see only previous tokens. This means the last token “saw” all available context - it contains the most complete information!
Example of generation in action
Let’s see how this works with a concrete example:
Prompt: “Write a story about how my learned cat said that he…"
The model processes this text through all layers. The attention mechanism weighs the features of each word. If the model was trained on Russian folk tales (for example, on Afanasyev’s collection), then the word “said” will get a high weight in connection with “cat” - after all, it knows about Kot-Bayun.
But if the model had never encountered talking cats, it might consider the connection “cat → said” unlikely and would give this word a low weight.
When the model generates a continuation, it uses the hidden state of the last token (“he…”) and predicts the next word based on what most often appeared in similar contexts during training.
Model response: “has seen much and knows much”
This is how the model continued the text in the style of Russian folk tales - precisely because it was trained on them and “remembered” the characteristic phrases of Kot-Bayun.
Summary: how everything works together
Let’s put the whole picture together:
- Embeddings - turn words into coordinate vectors in semantic space
- Attention (Q, K, V) - finds connections between words, enriches with context
- Multi-head - looks at text from 8-12 different points of view simultaneously
- FFN - deeply processes each word with a neural network with nonlinearities
- Transformer layer - this is Attention + FFN with residual connections
- 24 layers - gradually create an increasingly abstract understanding of text
- KV-cache - speeds up generation by saving Keys and Values from old tokens
- Hidden state - final representation of a token, used for prediction
Actually, that’s enough for now. Of course, there are still a bunch of details - positional encoding, normalization, training techniques. But the foundation is exactly what we’ve covered.
Now, when they ask you about transformers at an interview - you’re quite capable of getting out of it)

Now you know how transformers work!